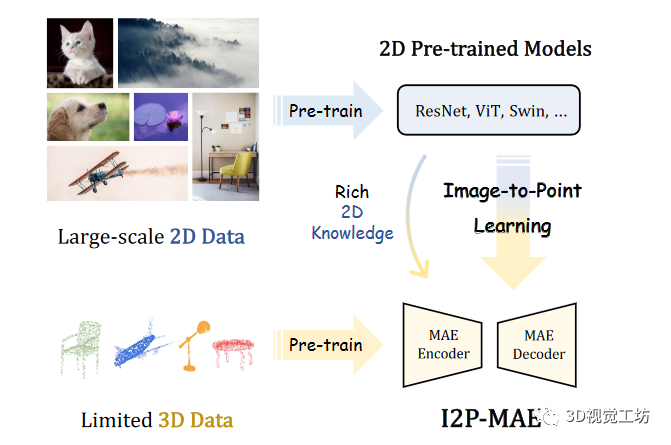
考虑到二维预训练模型的普及,由于昂贵的数据采集和劳动密集型标注,大规模三维数据集仍然缺乏预训练模型。广泛采用的ShapeNet仅包含55个对象类别的5万个点云,远低于二维视觉中的1400万ImageNet和4亿图像-文本对。考虑到图像和点云的同源性,它们都描述了物体的某些视觉特征,并通过2D-3D几何映射相关联,我们提出了这样一个问题:现成的2D预训练模型能否通过将稳健的2D知识转移到3D领域来帮助3D表示学习?为了应对这一挑战,我们提出了I2P-MAE,这是一种掩码自动编码框架,可进行图像到点的知识转移,用于自监督三维点云预训练。具体来说,参考左中的三维MAE模型,我们首先采用非对称编码器-解码器变换器作为三维预训练的基本架构,将随机遮蔽点云作为输入,并从可见点重建遮蔽点。然后,为了获得三维形状的二维语义,我们通过将点云有效地投射到多视角深度图中来弥补模型差距。这不需要耗时的离线渲染,并在很大程度上保留了不同视角下的三维几何图形。在此基础上,我们利用现成的二维模型获得多视角二维特征以及点云的二维显著性图,并分别从两个方面指导预训练,如右图所示。这里也推荐「3D视觉工坊」新课程《彻底搞懂基于Open3D的点云处理教程!》。
本文的主要贡献如下:
我们提出了图像到点掩码自动编码器(I2P-MAE),这是一种利用二维预训练模型学习三维表征的预训练框架。
我们引入了两种策略:二维引导遮挡和二维语义重构,以有效地将学习到的二维知识转移到三维领域。
广泛的实验表明了我们的图像到点预训练的重要性。
二维预训练模型的日益成熟普及,而由于昂贵的数据采集和劳动密集型标注,大规模三维数据集仍然缺乏预训练模型。因此希望通过使用现成的2D预训练模型辅助3D模型训练。
在公众号「3D视觉工坊」后台,回复「原论文」即可获取论文pdf和代码。
添加,备注:3D点云,拉你入群。文末附行业细分群。
I2P-MAE的整体流程如下图所示,给定输入点云,我们利用二维预训练模型从投影深度图中生成两个引导信号:二维突出图和二维视觉特征。我们分别进行二维引导遮蔽和二维语义重构,将编码的二维知识用于三维点云预训练。被绿笔圈起来的就是图1的右图部分,要训练的就是encoder和decoder,loss发生在L3D和L2D处首先对input的点云P做最远点采样,采样后的点云记为T,对T进行mask,即选取一些点盖住,而选取哪些点盖住由2D-guidedMasking决定,将这些点输入encoderencoder中,输出网络预测的未mask的点和mask的点,然后将mask的点重建,和输入P比较,让它们尽量接近,并将未mask的点和2D网络输出的特征进行比较,让它们尽量接近未被绿笔框起来的即为利用2D图像去辅助的部分,这里直接用的现成的,训练好的网络,整个下面部分都是没有训练的。先把点云在三个方向投影,做成深度图,输入训练好的图像网络中,生成重要性map和特征map,重要性map用于选择mask点,特征map用于比较decoder生成的特征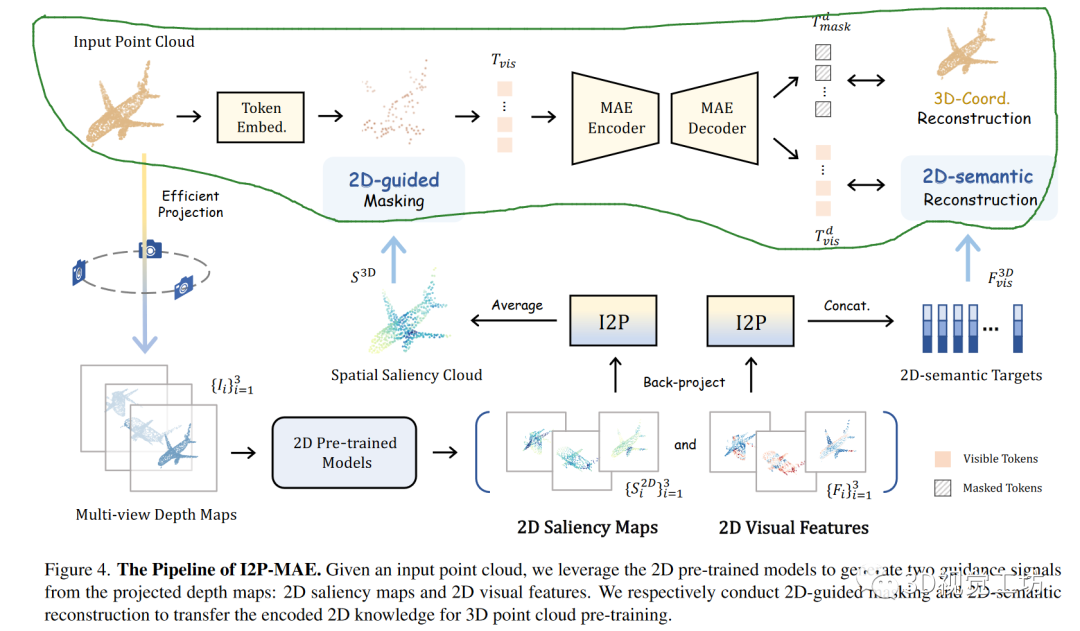
我们可以利用不同架构的二维模型(ResNet[26]、ViT[12])和各种预训练方法(监督[26,42]和自监督[5,50])来辅助三维表示学习。为了对齐二维模型的输入模态,我们将输入点云投影到多个图像平面上以创建深度图,然后将其编码为多视角二维表示。**EfficientProjection.**将输入点云P从三个正交视图中分别沿x、y、z轴进行投影。对于每一个点,我们直接省略其三个坐标中的每一个坐标,并将另外两个坐标向下舍入,从而得到其在相应地图上的二维位置。2DVisualFeatures.我们利用预训练的二维模型,例如预训练的ResNet或ViT,提取具有C通道的点云特征,这种二维特征包含了从大规模图像数据中学习到的足够高层次语义。2DSaliencyMaps.我们还通过二维预训练模型获取每个视图的语义突出图。单通道突出图表示不同图像区域的语义重要性。
在点云的二维预训练表示之上,I2P-MAE的预训练由两个图像-点学习设计引导:编码器之前的二维引导遮蔽和解码器之后的二维语义重构。2D-guidedMasking.传统的掩码策略是按照均匀分布随机采样被掩码的标记,这可能会阻止编码器"看到"重要的空间特征,并使解码器受到非重要结构的干扰。因此,我们利用二维语义突出图用于指导点标记的屏蔽,从而采样更多具有语义意义的三维部分进行编码。具体地说,我们以点标记为索引,将多视角的2DSaliencyMaps反向投影回三维空间,并将其聚合为点云S3D。I2P()表示图5中2D到3D的反投影操作。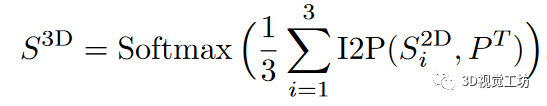
2D-semanticReconstruction.屏蔽点标记的三维坐标重构使网络能够探索低层次的三维模式。在此基础上,我们进一步利用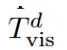
来重构从不同视图中提取的二维语义,从而有效地将二维预训练知识转移到三维预训练中。

由于多视角深度图从不同角度描绘了三维形状,多视角二维特征之间的串联可以更好地整合二维预训练模型所继承的丰富语义。此处计算l2D损失为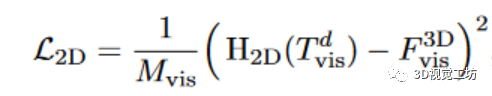
3D-coordinateReconstruction.在解码点令牌的基础上,重建被遮挡令牌及其k个相邻点的三维坐标。通过倒角距离计算损失,并将其表示为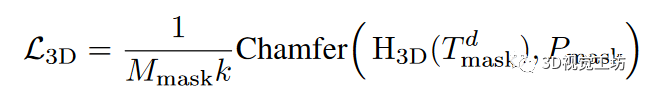
总损失可表示为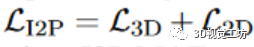
我们采用流行的ShapeNet进行自我监督三维预训练,其中包含57,448个合成点云和55个对象类别。为了进行公平比较,我们采用了与Point-M2AE相同的MAE变换器架构:3级编码器,每级5个块;2级解码器,每级1个块;2,048个输入点数(N);512个下采样点数(M);16个近邻点数(k);384个特征通道(C);掩码率为80%。对于现成的二维模型,我们默认使用由CLIP预训练的ViTBase,并在三维预训练时冻结其权重。我们将点云投影到三个224×224的深度图中,得到二维特征尺寸H×W为14×14。I2P-MAE预训练了300个epochs,批量大小为64,学习率为10-3。采用AdamW优化器,权重衰减为5×10-2,余弦调度器,预热10个epoch。为了评估传输能力,我们直接将I2P-MAE编码器提取的特征用于合成ModelNet40[66]和真实世界ScanObjectNN[60]的线性SVM,而不进行任何微调或投票。对于这两个领域的三维形状分类,I2P-MAE都表现出了卓越的性能,准确率分别超过第二名0.5%和3.0%。我们的SVM结果(93.4%,87.1%)甚至超过了SVM。
在预训练之后,I2P-MAE针对真实世界和合成三维分类以及部件分割进行微调。除ModelNet40外,我们不使用投票策略进行评估。Real-world3DClassification.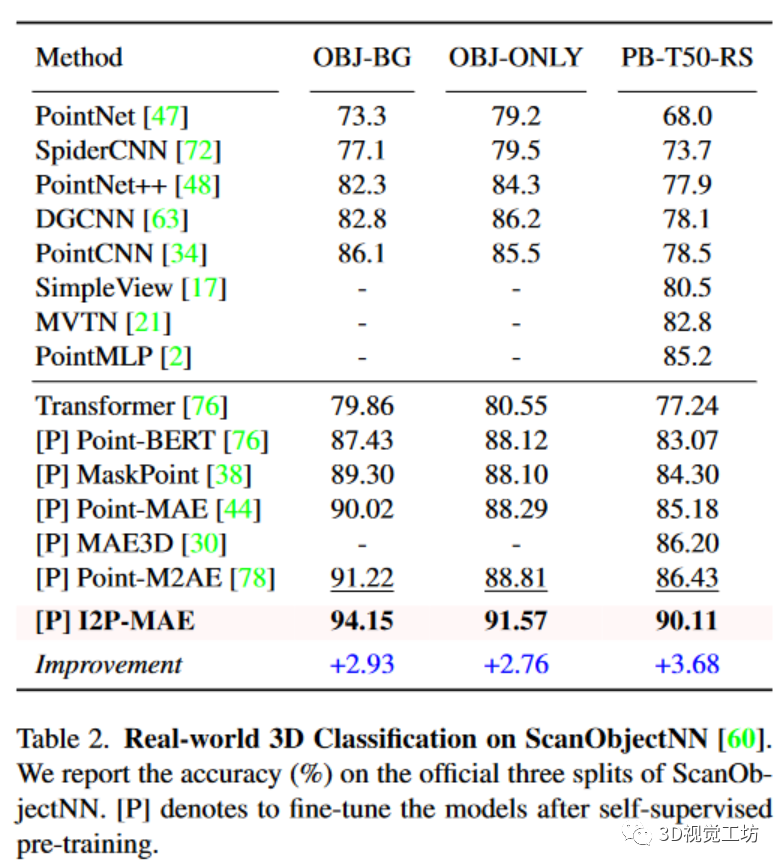
Synthetic3DClassification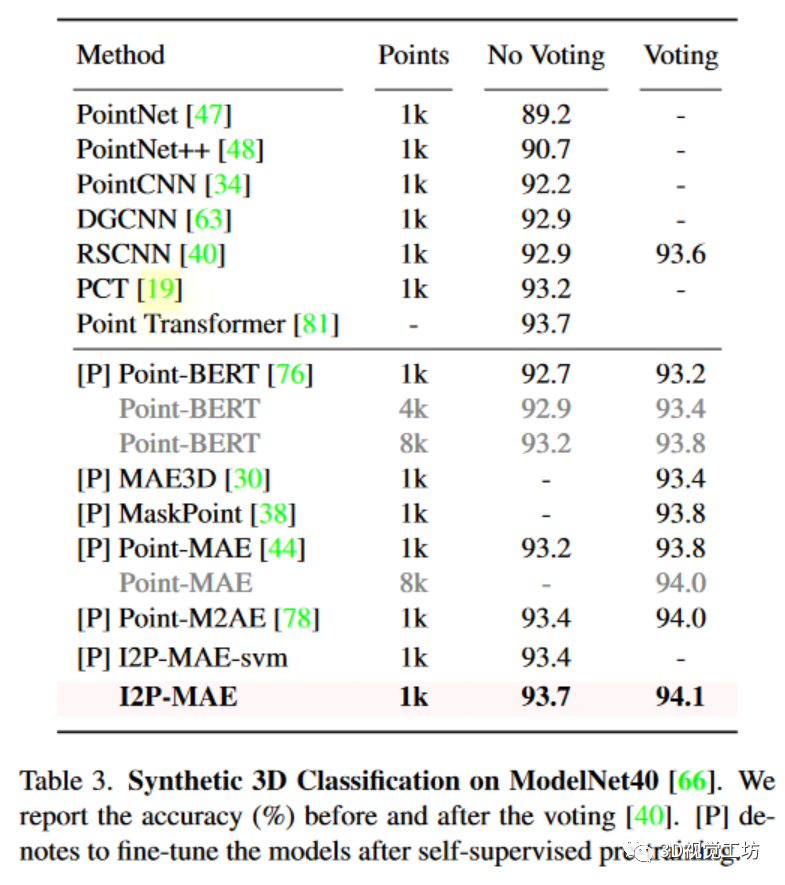
PartSegmentation.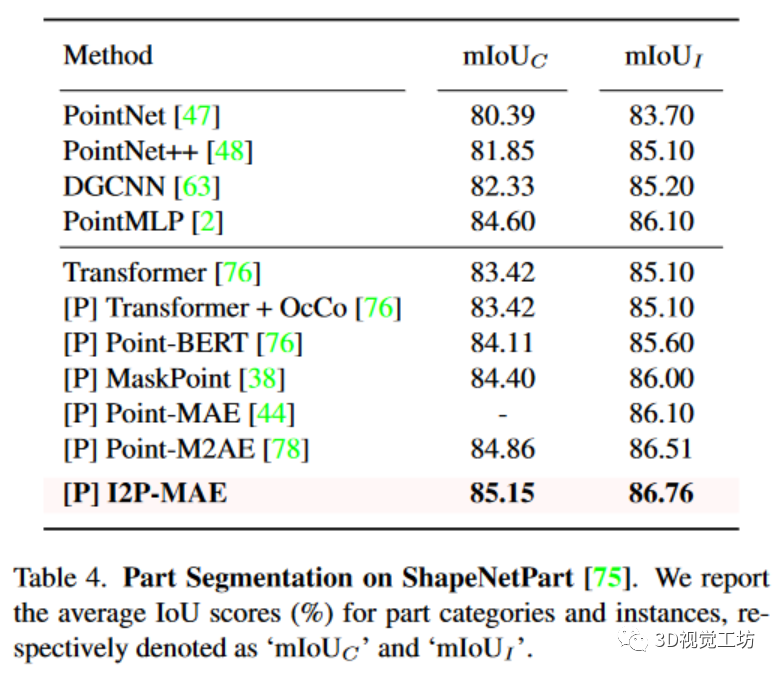
EAI-Stereo在三个不同的视觉数据集上(Middlebury、ETH3D、KITTI-2015)的表现在多个指标上表现最佳。在KITTI-2015数据集上,作者的方法通过在另一个数据集上的预训练和微调,在稀疏GroundTruth值上也有良好表现。该方法在进行简单的数据增强时也展现出了强大的泛化性能。2D-guidedMasking.在表5中,我们对I2P-MAE的掩码自动编码进行了不同掩码策略的实验。第一行表示我们的I2P-MAE采用了二维引导掩码,它为编码器保留了更多语义上重要的标记。与第二行的随机屏蔽相比,二维显著性图的引导在两个下游数据集上的分类准确率分别提高了0.4%和0.9%。然后,我们反转空间语义云中的标记得分,转而屏蔽最重要的标记。如第三行所示,SVM的结果在很大程度上受到了损害,分别为-0.9%和-3.3%,这表明了在编码器中对关键三维结构进行编码的重要性。最后,我们以±0.1的比例修改了掩码比率,该比率控制了可见标记和掩码标记之间的比例。性能衰减表明,二维语义重构和三维坐标重构需要很好地平衡,才能完成具有适当挑战性的预文本任务。这里也推荐「3D视觉工坊」新课程《彻底搞懂基于Open3D的点云处理教程!》。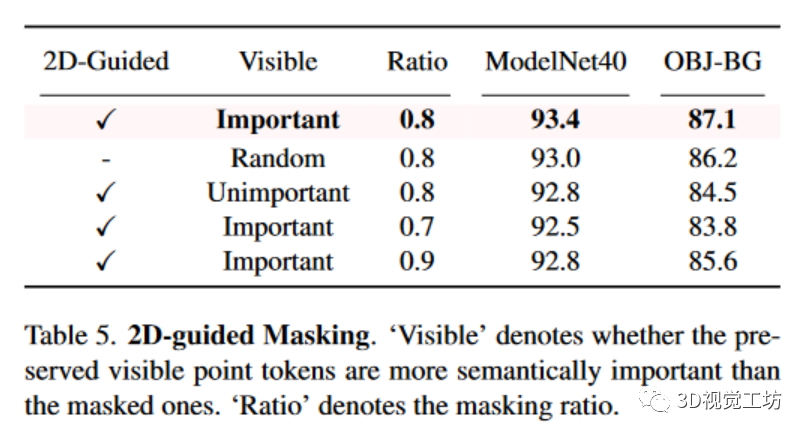

在本文中,我们提出了I2P-MAE,一种具有有效图像到点学习方案的掩蔽点建模框架。我们介绍了两种将学习到的二维知识转移到三维领域的方法:二维引导遮挡和二维语义重建。在二维引导的帮助下,I2P-MAE学习到了卓越的三维表征,并在三维下游任务中实现了最先进的性能,从而缓解了对大规模三维数据集的需求。在未来的工作中,不仅限于遮挡和重建,我们还将为三维遮挡自动编码器探索更充分的图像-点学习,例如点标记采样和二维-三维类标记对比。此外,我们希望我们的预训练模型能够使更多的三维任务受益。
6参考ICLR2023|2D视觉或语言FoundationModel可以帮助3D表征学习吗?_PaperWeekly的博客-CSDN博客
免责声明:本文章如果文章侵权,请联系我们处理,本站仅提供信息存储空间服务如因作品内容、版权和其他问题请于本站联系