最新消息!
在MetaAI发布CodeLlama后仅两天的时间,WizardLM团队基于该模型及其最新的对齐算法训练的在权威代码生成评测榜单HumanEval上即达到了惊人的73.2%pass@1分值,同时超越了Claude-2(71.2%),3月份版本的GPT-4(67.0%),以及最新的(72.5%)。与此同时,WizardCoder团队也在Github和HuggingFace开源了该模型细节及权重:
Github:
HuggingFace:

对于该全新代码模型,PaperWeekly团队将进行全面评测,并继续发布详细报道。今天,我们主要介绍Wizard家族的另一位重要成员WizardMath,及其数学能力超越的RLEIF算法。
前言
与此同时,在开源领域,由Meta主导发布的Llama2更进一步提升了开源模型在这一领域的表现,达到了新的先进水平。
然而,作者团队依然注意到,目前最佳开源模型Llama2在GSM8k任务上的通过率也仅约为56.8%,仍远低于包括GPT-4、ChatGPT、Claude、PalM2等在内的一众闭源模型性能。由于数学推理对于计算过程准确度与逻辑推理能力的严苛标准,因此追赶和提升难度也更高。
最近,在WizardLM团队相继开源WizardLM和WizardCoder模型后,又开源一款全新的数学推理大模型——WizardMath,它打破了闭源模型的垄断地位,显著超越OpenAI的ChatGPT,Anthropic的Claude以及Google的PaLM2等,在参数只有700亿远不及他们情况之下,成为新时代的开源领军者。
著名CMU科学家,MXNet,XGBooST,TVM等著名项目创建者,以及OctoML首席科学家陈天奇也祝贺WizardMath在开源大模型数学领域的突破。
甚至著名科学家YamPeleg也详细解读并转发WizardMath的论文:
也有国外大佬转发了WizardMath论文:


RLEIF(ReinforcedEvol-Instruct)方法
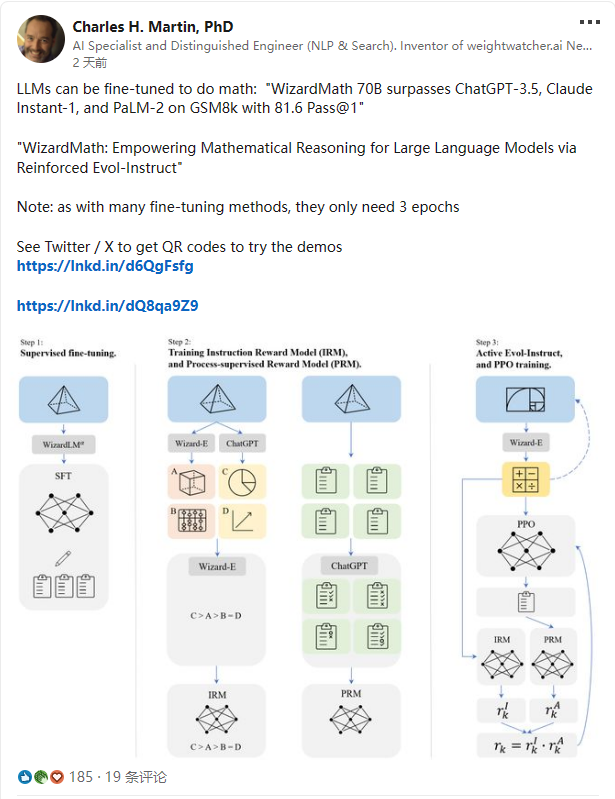
WizardMath取得成功主要依靠的就是一种成为RLEIF的全新强化学习方法。受WizardLM的Evol-instruct和OpenAI过程监督的强化学习PRMs的启发,作者提出一个新范式:基于强化学习的指令进化方法ReinforcedEvol-Instruct,旨在增强LLaMA-2数学推理能力,如Figure1表示,主要包含三步:
1)SFT
2)训练指令奖励模型和过程奖励模型
3)进行ActiveEvol-Instruct和PPO训练
1.SFT:按照InstructGPT,作者首先用生成的有监督指令对Llama2进行微调,包含两部分:
为了让模型解析每一步更简单,作者用WizardLM70B模型对GSM8k和MATH原有训练集15k数据采用few-shot方式重新生成15k答案,从而使生成的答案具有step-by-step的格式,然后过滤掉不正确的问题答案;
为了增强指令数据多样性和模型泛化能力,从WizardLM的训练数据中随机采样了1.5k个开放域对话样本。将上面两部分数据合并一起作为最终的SFT数据,用于指令微调Llama2模型。
2.数学指令进化范式:为了增加指令数据的复杂度和多样性,同时受该团队另外两篇工作WizardLM和WizardCoder指令进化的启发,从两个方面进行着手:
向下进化,让问题变得更简单,比如将高难度问题进化为较低难度的问题或者产生一个不同话题的全新的更简单的指令;
向上进化,遵从WizardLM论文中原先指令进化方法,通过添加更多约束条件,问题具体化,和增加推理三个维度来深化并产生新的更困难的问题。
3.受InstructGPT和PRMs启发,训练两个奖励模型来预测生成的指令质量和相应答案的每一步正确性:
指令奖励模型IRM:从定义,精确度和完整性三个方面判断进化的指令的质量。对于每一个初始指令,使用Wizard-E和ChatGPT分别生成2到4个进化指令,然后使用Wizard-E模型对这些生成的指令进行质量排序,从而得到IRM的训练数据;
基于过程监督的奖励模型PRM:使用ChatGPT对所有问题的解决步骤评判是否正确;
PPO训练:对GSM8k和MATH数据总共进化8轮,最终数据能从15k增长到96k。对每个指令使用IRM模型对指令的质量进行打分(rI),同时对答案使用PRM模型对每个解题步骤进行评判是否正确(rA),最后用r=rIxrA公式作为模型最终奖励,从而用于训练PPO。

实验
3.1测试集
作者主要在两个常用数学推理基准测试集(GSM8k和MATH)上评估WizardMath。GSM8k数据集包含大约7500个训练数据和1319个测试数据,主要是小学水平的数学问题,每个问题都由基本的算术运算(加、减、乘、除)组成,一般需要2到8个步骤来解决。
MATH数据集收集来自著名数学竞赛问题(如AMC10、AMC12和AIME)。它包含7500个训练数据和5000个具有挑战性的测试数据,涉及七个学术领域:预备代数、代数、数论、计数与概率论、几何学、中级代数和微积分。这些问题被分为五个难度等级,'1'表示相对较低的难度等级,'5'表示最高的难度等级。
3.2训练和测试Prompt
训练WizardMath的Prompt格式来自Alpaca,如下:
测试时采用了CoT方式进行评估,如下:

结果
作者与大量基线模型进行性能比较,包括闭源LLM模型:OpenAI的GPT-3、、ChatGPT、GPT-4,谷歌的PaLM、PaLM2、Minerva,Anthropic的ClaudeInstant、、Claude2,DeepMind的Chinchilla;开源LLM模型:Llama1、Llama2、GAL、GPT-J、GPT-Neo、Vicuna、MPT、Falcon、Baichuan、ChatGLM、Qwen和RFT等。
4.1与闭源模型比较
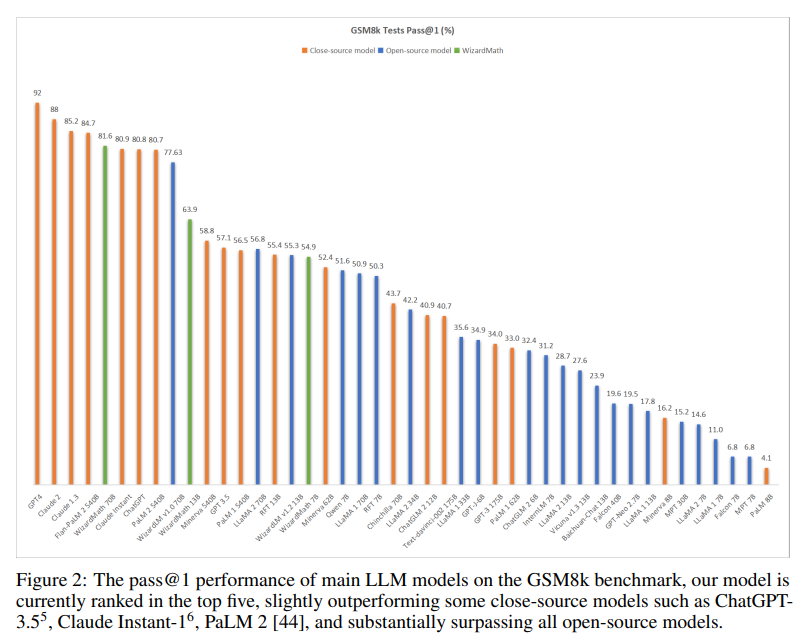
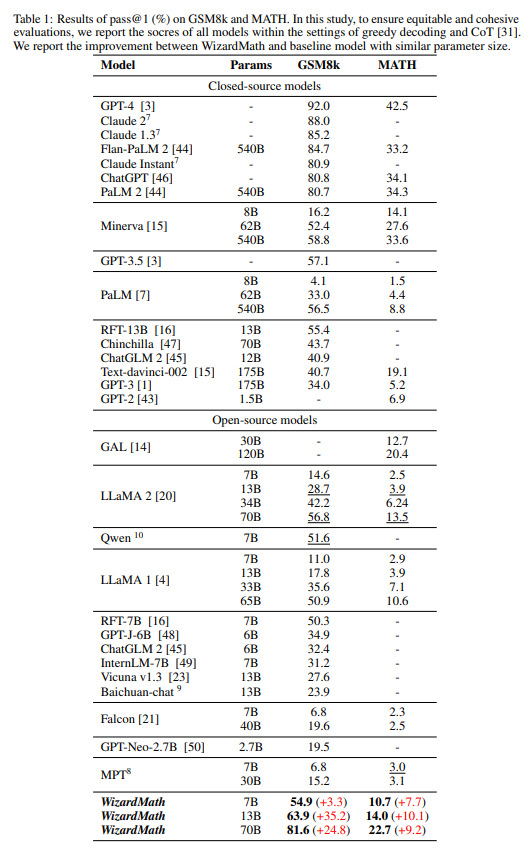
表1中,在GSM8k上,WizardMath显著超过一些闭源LLM模型,包括OpenAI的ChatGPT,Google的PaLM1和PaLM2,Anthropic的ClaudeInstant;同时WizardMath目前在所有模型上排名前五,如图二所示。在MATH数据集上WizardMath70B超越了Text-davinci-002.
详细结果如下:
1.WizardMath13B在GSM8k上优于PaLM1540B(63.9)、Minerva540B(63.9)和(63.9)。同时,它在MATH上超越了PaLM1540B(14.0)、GPT-3175B(14.0);
2.WizardMath70B在GSM8k上超过ClaudeInstant(81.6)、ChatGPT(81.6)和PaLM2(81.6)。同时,WizardMath70B在MATH上超过了Text-davinci-002(22.7比19.1)。
4.2与开源模型比较
表1中所示的结果表明,WizardMath70B在GSM8k和MATH基准测试中大幅度超过所有开源模型。详细结果如下:
1.WizardMath7B超越了大多数参数量从7B到40B之间的开源模型,包括MPT、Falcon、Baichuan-chat、、ChatGLM2、Qwen、Llama1和Llama2;
2.WizardMath13B在GSM8k上明显优于Llama165B(63.9)和Llama270B(63.9)。同时它在MATH上的表现远远优于Llama165B(14.0)和Llama270B(14.0);
3.WizardMath70B在GSM8k上超越了Llama270B(81.6),提升24.8个点。同时它在数学方面也比Llama270B(22.7比13.5)高出9.2个点。
WizardLM团队在开源LLM研发上表现异常耀眼,多项世界公认大模型基准能力测评中比肩闭源巨头(OpenAI和Anthropic),这到底是怎么样的一个团队,对于大模型技术有怎样的理解和认知,外界多有好奇。PaperWeekly有幸采访到该团队负责人,来自微软的大模型专家徐粲来深入解读WizardLM背后的技术原理。
徐粲,微软高级应用科学家,之前曾在微软小冰和微软亚研院从事聊天机器人系统研究。在NeurIPS、ICLR、ACL、EMNLP、CVPR、ICCV等国际学术顶级会议发表论文30余篇,谷歌总引用1300+次。
|PaperWeekly:最近我们注意到WizardMath在国际认可的数学基准Gsm8k上面超过了,使用了一种称为RLEIF的强化学习方法,它跟OpenAI提出的RLHF方法有什么优势?
|PaperWeekly:从Evol-Instuct到新近的RLEIF,和大部分做大模型团队强调参数量和数据相比,似乎你们更看重独创性的方法?大部分人似乎觉得大模型只要参数量足够多,数据质量足够好就可以取得很好的效果。
徐粲:我本人比较认可竞争优势来自于差异化的认知,参数量越大,数据质量越高肯定大模型训练效果越好,我并不反对这种观点,但是这种观点几乎为所有人所知晓,这一点无法构成优势。从一开始做WizardLM我就想的比较清楚,如果沿用OpenAIPreTrain-SFT-RLHF的框架,作为后来追赶者几乎是鲜有机会胜出的,唯有自创流派自建技术体系才能形成差异化优势,我从现实场景中ChatGPT处理较复杂指令吃力这一点入手,提出“指令进化论”,像生物进化历程一样,逐步由简单指令进化成复杂指令进行大模型训练,这种方式可以在不增加参数量的情况下大幅提升模型能力。后来我们在指令近进化的框架下又完成了强化学习版本RLEIF,进一步提升了指令进化的效力。后续我们还会围绕指令进化的方方面面做出改进,做出更强的指令进化术使得单位参数量拥有更强的模型性能。
|PaperWeekly:看样子未来我们可以看到更多版本的Evol-Instruct。Evol-Instruct最早版本使用了ChatGPT的输出作为回复,而在最新的WizardMath中已经几乎不再使用ChatGPT,这种变化的出发点是什么?
徐粲:首先,ChatGPT输出的质量并不是绝对的高,尤其是数学等较为高精尖的领域,ChatGPT的回复质量其实并不十分理想。随着我们Wizard家族模型水平逐步提升,通过解码出大量回复加质量筛选的模式我们自己模型输出的回复质量慢慢地已经达到ChatGPT水平,慢慢地实现了对ChatGPT回复的替代。我们还用少量的ChatGPT来帮助我们进行指令进化,之如前面所说,“指令进化”是我们技术体系的核心,我们慢慢地也在构建自己的指令进化器即RLEIF里面的Wizard-E模型,它在指令进化上面可以做的比ChatGPT还要好。
|PaperWeekly:早在网上爆料出GPT4采用多专家的MOE架构之前,似乎WizardLM就已经在考虑多专家发展路线,很早推出了WizardCoder这一专注coding的模型,到最近专注数学的WizardMath模型,这块你们当时具体的考虑是怎么样的?
徐粲:我不太喜欢MOE的架构,因为它会带来参数量的增大,让模型变笨重。我们很早就注意到大模型的后预训练中有一种“技能墙”效应的存在。和人类学习知识过程不太一样,大模型学习不同门类的技能不一定会相互促进,反而有时候会相互伤害。多专家+MOE的架构是一种有效的破除技能墙的方法,除了低效外。在最开始Wizard家族做多专家时候我们确实是奔着组MOE去的,但我们也在积极寻找更好的办法来破除技能墙,如果能够找到或许就不会再像GPT4一样采取MOE架构。
|PaperWeekly:现在Wizard大模型家族已经有三位成员,后续还会有第四位成员吗?
徐粲:目前有第四位成员的计划,但是还没有完全想清楚它的特点,前三位成员定位清晰且已经都有很大的scope。
|PaperWeekly:WizardMath如果专注于数学领域,似乎它的scope并不是很大?
徐粲:数学本身就是极其庞大深奥且足够底层的学科。目前WizardMath主要能力还是在解决给定的数学问题上面,如何自己发现问题,提出假设,进行推导验证这一整套数学研究的流程WizardMath后续还会深入的学习,另外WizardMath,我期望它的未来长期规划是在多个理工科学科(如物理,化学,生物等)上面达到博士的水平,将来会逐步成长为综合性科学推理计算平台,来帮助人类理解、处理各种深奥复杂的科学事务。当WizardMath在各个学科都有了一定积累后,我们会让它去参加一些国内外的大学或者职业考试来检验自己的学习成果。
|PaperWeekly:我看你提到一个推理计算平台的概念,似乎你并不认为它仅仅是一个模型。
徐粲:对,我认为对于大模型来说,模型即应用即平台。太多人将模型,应用,平台三者割裂来看,其实我对Wizard家族规划成多专家除了做MOE的考虑外,更多是希望其往不同的应用平台能力去发展,比如WizardLM其擅长语言能力,除了基础的语言功底外,可以慢慢地发展出情感计算,虚拟人格,虚拟世界,成为综合性语言平台,任何跟语言能力强相关的应用它都可以完成。类似地,WizardMath除了帮你解题外,还可以帮你做理财,做数据分析,任何你可以用语言定义的应用需求,本质上大语言模型都可以直接帮你处理完成,这种情况下大语言模型本身就一个应用平台旗舰。WizardCoder后续除了基本的帮你写代码外,我对他后续期望和规划是逐步成长为完全的自动agent可以在互联网世界自由行动。
|PaperWeekly:我们看到,现在基于全新的CodeLlama训练的WizardCoder-Python34B模型,在代码生成领域同时击败了GPT-4与Claude-2,那么拥有最强代码模型后,你们接下来的计划是什么呢?
徐粲:是的,WizardCoder在最权威的HumanEval上超越了GPT-4的3月份版本,但是我们依然需要认识到GPT-4的强大,它其实一直在进化,根据我们的评测,最新的GPT-4已经达到了82%的HumanEvalpass@1,这就是我们接下来的关键目标之一。而对于Claude,我们也是同样的态度。
|PaperWeekly:WizardLM是开源LLM顶级对齐团队,OpenAI刚刚成立了Superalignment团队来加大对齐领域的投入,你们后续在预训练方面有没有打算或者投入?
徐粲:我们其实已经开始在预训练技术上展开研究,但是我们的方法会和主流预训练方法不太一样。因为我们的后预训练阶段基于指令进化论构建,我们在预训练阶段也会引入相应的指令进化方法,一边对预训练语料进行进化形变,一边进行预训练,以期望彻底打开指令进化的所有空间和可能性。
|PaperWeekly:目前来看,你们主要在语言大模型发力,未来在多模态大模型领域,你们后续会进行研发投入吗?
徐粲:我们在多模态领域有计划,目前也在结合语言大模型和视觉大模型做一些新形态的应用尝试,很快我们会发布我们的beta测试版。
|PaperWeekly:目前开源LLM进展飞速,你们作为开源LLM非常活跃的一分子。怎么看待像OpenAI,Claude等闭源LLM和开源LLM的未来?
免责声明:本文章如果文章侵权,请联系我们处理,本站仅提供信息存储空间服务如因作品内容、版权和其他问题请于本站联系