文章概述了每个模式,并详细描述了为什么它重要,以及如何应用它,借鉴了大量的学术研究和行业资源。旨在提炼最佳实践,以开发高质量、可扩展和安全的LLM系统。
内容兼具理论深度和实操性,行文简洁,深入浅出,是目前少有的梳理LLM系统和产品构建范式的好文章,值得大模型从业者参考。
以下为ChatGPT翻译、我粗校的版本,疏漏之处,文责在ChatGPT。
有一类问题很容易想象并制作演示,但要将其变成产品却非常困难。例如,自动驾驶:演示一辆汽车在街区内自动驾驶很容易,但要将其打造成产品需要十年的时间。
——Karpathy
这篇文章是关于将大型语言模型(LLMs)整合到系统和产品中的实用模式。我们将借鉴学术研究、行业资源和从业者的经验,试图将它们提炼成关键的思想和实践。
有七个关键模式。我还按照提高性能与降低成本/风险的程度以及接近数据与接近用户的程度进行了组织。
评估:衡量表现
RAG:添加最近的、外部的知识
微调:提高特定任务的能力
缓存:为了减少延迟和成本
护栏:确保产出质量
防御性用户体验:优雅地预测和处理错误

LLM模式:从数据到用户,从防御到进攻
一、评估:衡量表现为什么要评估?评估使我们能够衡量我们的系统或产品的表现,并检测任何退步。一个系统或产品可以由多个组件组成,例如LLMs、提示模板、检索到的上下文和温度等参数。一组代表性的评估结果使我们能够在规模上测量系统变化的一步。没有评估,我们将是盲目行动,或者每次更改都需要目视检查LLM输出。
更多关于评估的内容在语言建模领域有许多基准。其中一些值得注意的是:
MMLU:一套包含57个任务的内容,涵盖了初等数学、美国历史、计算机科学、法律等多个领域。为了表现出色,模型必须具备丰富的世界知识和问题解决能力。
EleutherAIEval:通过零/少样本设置在200个任务上测试模型的统一框架。包括大量的评估,如BigBench、MMLU等。
HELM:HELM不仅仅评估LLMs的具体任务和指标,还提供了全面的评估。这些指标包括准确性、校准性、鲁棒性、公平性、偏见、有害性等。任务包括问答、信息检索、摘要、文本分类等。
AlpacaEval:自动评估框架,用于衡量强大的LLM(例如GPT-4)在多大程度上更喜欢一个模型的输出而不是参考模型。指标包括胜率、偏差、延迟、价格、方差等。经验证与2万个人工注释具有高度一致性。
我们可以将指标分为两类:依赖于上下文或者独立于上下文。
依赖上下文:这些考虑到上下文因素。它们通常是为特定任务提出的;如果要将它们用于其他任务,需要进行一些调整。
无上下文:在评估生成的输出时,这些不与上下文相关;它们只是将输出与提供的黄金参考进行比较。由于它们与任务无关,因此更容易应用于各种任务。
为了更好地了解这些指标(以及它们的潜在不足),我们将探讨一些常用的指标,如BLEU、ROUGE、BERTScore和MoverScore。
BLEU(双语评估助手)是一种基于精确度的度量标准:它计算生成的输出中与参考文本中出现的n-gram数量,并将其除以输出中的总词数。它主要用于机器翻译,并因其成本效益而保持着流行度。
首先,计算不同值的精确度:

是指在任何相应的参考句子中,n-gram出现的最大次数。

在计算了各种的精确度之后,最终的BLEU-N分数是所有分数的几何平均值。
然而,由于精确度仅依赖于n-gram,并不考虑生成输出的长度,因此仅包含一个常见词(如停用词)的单个unigram的输出将达到完美的精确度。这可能会误导并鼓励输出结果中包含更少单词以提高BLEU分数。为了应对这个问题,我们会添加简洁度惩罚来惩罚过于短的句子。

因此,最终的公式是:

ROUGE(召回导向的Gisting评估):与BLEU相比,ROUGE是以召回为导向的。它计算参考文本中与输出文本相同的单词数量。通常用于评估自动摘要任务。
有几种ROUGE变体。ROUGE-N与BLEU最相似,它也计算输出和参考之间的n-gram匹配数量。
其他变体包括:
ROUGE-L:这个指标衡量了输出和参考之间的最长公共子序列(LCS)。它考虑了句子级别的结构相似性,并聚焦于最长的连续出现的n-gram序列。
ROUGE-S:这个指标衡量了输出和参考之间的跳跃二元组。跳跃二元组是一对单词,无论它们之间可能夹杂了哪些单词,它们都保持了它们在句子中的顺序。
BERTScore是一种基于嵌入的度量标准,它使用余弦相似度来比较生成的输出中的每个标记或n-gram与参考句子。BERTScore有三个组成部分:
召回率:参考文本中每个标记与生成输出中最接近的匹配项之间的平均余弦相似度。
精确度:生成输出中每个标记与参考中最接近的匹配之间的平均余弦相似度。
F1:召回率和精确率的调和平均值
BERTScore非常有用,因为它可以考虑到同义词和改写。而像BLEU和ROUGE这样的简单度量指标由于依赖于精确匹配,所以无法做到这一点。研究表明,BERTScore在图像字幕和机器翻译等任务中具有更好的相关性。
MoverScore还使用上下文嵌入来计算生成输出和参考之间的标记距离。但与基于一对一匹配(或“高对齐度”)的BERTScore不同,MoverScore允许多对一匹配(或“软对齐度”)。
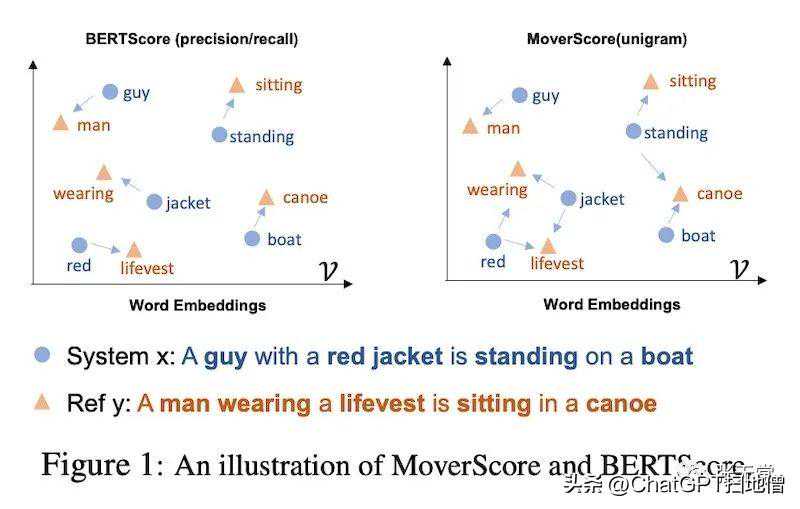
MoverScore能够将一个序列中的语义相关词映射到另一个序列中的对应词。它通过解决一个受限制的优化问题来实现,找到将一个文本转化为另一个文本所需的最小努力。这个想法是测量单词在转换一个序列到另一个序列时需要移动的距离。
然而,使用这些传统的基准和指标存在一些陷阱。
首先,这些指标与人类评判之间存在较差的相关性。BLEU、ROUGE、METEOR等指标有时与人类评估流畅性的相关性呈负相关。特别是对于需要创造力和多样性的任务,BLEU和ROUGE的相关性较低。此外,即使对于同一指标,在不同研究中报告的方差也很高。这可能是由于收集人类判断的方法差异或不同的指标参数设置所致。
其次,这些指标通常对更广泛的任务适应性较差。将一个任务提出的指标应用到另一个任务上并不总是明智的选择。例如,像BLEU和ROUGE这样的精确匹配指标并不适用于抽象摘要或对话等任务。由于它们基于输出和参考之间的n-gram重叠,所以对于可能有多种回应的对话任务来说,它们并没有意义。一个输出可以与参考没有任何n-gram重叠,但仍然可以是一个好的回应。
第三,即使有最近的基准测试,如MMLU,同一模型在评估实现上的得分也可能有显著差异。Huggingface将原始的MMLU实现与HELM和EleutherAI的实现进行了比较,发现同一个示例在不同的实现中可能有不同的提示。

在不同的MMLU实现中,对于同一个问题有不同的提示
此外,对于这三个基准测试,评估方法也存在差异:
原始MMLU:仅比较对答案(A、B、C、D)的预测概率
HELM:根据模型的下一个标记概率选择具有最高概率的标记,即使它不是选项之一。
EleutherAI:计算每个答案的完整答案序列的概率(即,一个字母后面跟着答案文本)。然后,选择概率最高的答案。

同一问题在不同的MMLU实现中有不同的评估方式
因此,即使对于相同的评估,根据评估实施的不同,绝对分数和模型排名也可能会有很大的波动。这意味着,即使是对于相同的评估,模型指标也无法真正进行比较,除非评估的实现在细节上完全相同,如提示和标记化。
除了上述传统的评估方法之外,一种新兴的趋势是使用强大的LLM作为其他LLM生成的无参考度量标准。这意味着我们可能不需要人工评判或黄金参考来进行评估。
G-Eval是一个框架,它应用了具有CoT(思维链)和填充形式的LLM来评估LLM的输出。首先,他们向LLM提供任务介绍和评估标准,并要求其生成评估步骤的CoT。然后,为了评估新闻摘要的连贯性,他们将提示、CoT、新闻文章和摘要连接在一起,并要求LLM输出一个介于1到5之间的分数。最后,他们使用LLM输出标记的概率来归一化分数,并将它们加权求和作为最终结果。

G-Eval概述
他们发现,作为一个评估器,GPT-4与人类判断有很高的斯皮尔曼相关性(0.514),超过了所有以前的方法。它在连贯性、一致性、流畅性和相关性等方面也超过了传统指标。在话题聊天中,它在自然度、连贯性、吸引力和基础性等多个标准上表现优于传统指标,如ROUGE-L、BLEU-4和BERTScore。
维库纳论文采用了类似的方法。他们首先定义了八个类别(写作、角色扮演、提取、推理、数学、编码、STEM和人文/社会科学),然后为每个类别开发了10个问题。接下来,他们从五个聊天机器人(LLaMA、Alpaca、ChatGPT、Bard和维库纳)生成了答案。最后,他们要求GPT-4根据帮助性、相关性、准确性和细节对答案的质量进行评分。
总体而言,他们发现GPT-4不仅提供了一致的评分,还能对这些评分给出详细的解释。在单一答案评分范式下,GPT-4与人类的一致性更高(85%),而人类之间的一致性则较低(81%)。这表明GPT-4的判断与人类评估者非常接近。
QLoRA还使用了LLM来评估另一个LLM的输出。他们要求GPT-4对Vicuna基准测试中的各种模型与的性能进行评分。根据和另一个模型的回答,GPT-4被要求给出10分的评分并解释其评级。他们还通过对模型进行直接比较来衡量性能,将任务简化为一个包含并列的三级评分体系。
为了验证自动评估的有效性,他们在Vicuna基准上收集了人工判断。使用MechanicalTurk,他们聘请了两名注释员对进行比较,并聘请了三名注释员进行成对比较。他们发现人类和GPT-4模型的排名基本一致,在模型层面上的Spearman等级相关系数为0.55。这提供了另一个数据点,表明基于LLM的自动评估可能是人工评估的一种经济高效且合理的替代方案。
如何申请评估?构建稳定的评估应该是任何基于LLM的系统或产品(以及传统的机器学习系统)的起点。
不幸的是,对于更复杂的任务,如抽象摘要或对话,传统的度量标准如BLEU和ROUGE并不适用。此外,我们发现像MMLU这样的基准测试对于其实施和测量方式非常敏感。坦白说,除非你的LLM系统是为了学校考试而学习,否则使用MMLU作为评估并不太合理。
因此,我们可以开始收集一组特定任务的评估(即提示、上下文和预期输出作为参考),而不是使用现成的基准。这些评估将指导提示工程、模型选择、微调等工作。随着我们对系统进行调整,我们可以运行这些评估来快速衡量改进或退步。把它看作是评估驱动开发(EDD)。
除了评估数据集,我们还需要有用的度量标准。它们帮助我们将性能变化提炼成一个可比较的单一数字。如果我们能简化问题,我们可以选择更容易计算和解释的度量标准。
最简单的任务可能是分类:如果我们在使用LLM进行分类任务(例如毒性检测、文档分类)或者没有对话的抽取式问答,我们可以依靠标准的分类指标,如召回率、精确度、PRAUC等。如果我们的任务没有正确答案,但我们有参考资料(例如机器翻译、提取式摘要),我们可能不得不依赖于基于匹配的较低质量参考度量(如BLEU、ROUGE)或语义相似度(BERTScore、MoverScore)。
然而,这些指标可能对于更开放性的任务(如抽象摘要、对话等)不适用。此外,收集人工判断可能会很慢且昂贵。因此,我们可以选择依靠强大的LLM进行自动评估。与通常存在噪声的人工判断(由于注释者之间的不同偏见)相比,LLM的判断往往更少噪声(因为偏见更加系统化),但更有偏见。但是,如果我们意识到这些LLM的偏见,我们可以相应地减轻它们。
位置偏见:像GPT-4这样的LLM倾向于偏爱第一个位置的回答。为了减轻这种偏见,我们可以在交换顺序时对相同的回答对进行两次评估。如果同样的回答在两种顺序中都被优先选择,我们将其标记为胜利。否则,就是平局。
冗长偏见:LLMs倾向于偏爱冗长、啰嗦的回答,而不是更简洁明了、质量更高的回答。一个可能的解决方案是确保比较回答在长度上相似。
自我增强偏差:LLMs对自己的答案有轻微的偏向。GPT-4在胜率上对自己有10%的优势,而Claude-v1在胜率上对自己有25%的优势。为了对抗这一点,在评估任务中不要使用相同的LLM。
另一个提示:与其直接要求LLM进行评估(通过给出分数),不如给出一个参考并要求进行比较。这有助于减少干扰。
最后,有时候最好的评估是人工评估,也被称为氛围检查(不要与名字不太好的代码评估基准HumanEval混淆)。正如在与MosaicML的潜在空间播客中提到的(第34分钟):
二、检索增强生成:添加知识检索增强生成(RAG)从基础模型外部获取相关数据,并利用这些数据增强输入,以提供更丰富的上下文来改善输出。为什么选择RAG?
RAG通过将模型基于检索到的上下文进行实际应用,有助于减少幻觉,从而提高事实性。此外,与持续预训练LLM相比,保持检索索引的最新状态更加经济实惠。这种成本效益使得通过RAG为LLMs提供最新数据变得更加容易。最后,如果我们需要更新或删除偏见或有毒文件等数据,更新检索索引就更加直接了当。
简而言之,RAG将信息检索领域的成熟且更简单的思想应用于支持LLM生成。在最近的Sequoia调查中,88%的受访者认为检索将是他们技术栈的关键组成部分。
关于RAG的更多信息在深入了解RAG之前,了解文本嵌入的基本概念会有所帮助。(如果您对这个主题很熟悉,可以跳过这一部分。)
文本嵌入是文本数据的压缩抽象表示,可以将任意长度的文本表示为数字向量。通常从文本语料库(如维基百科)中学习。将其视为文本的通用编码,其中相似的项目彼此靠近,而不相似的项目则相距较远。
一个好的嵌入是在下游任务中表现良好的嵌入,比如检索相似的项目。Huggingface的大规模文本嵌入基准(MTEB)对各种模型在分类、聚类、检索、摘要等多样化任务上进行评分。
RAG的起源可以追溯到开放领域的问答。早期的Meta论文表明,通过使用TF-IDF检索相关文档,并将其作为上下文提供给语言模型(BERT),可以提高开放领域问答任务的性能。他们将每个任务转化为一个填空陈述,并向语言模型查询缺失的标记。
在此之后,密集通道检索(DPR)表明,使用密集嵌入(而不是像TF-IDF这样的稀疏向量空间)进行文档检索可以超越强大的基准模型,如LuceneBM25(65.2%%的前五准确率。他们还表明,更高的检索精度会转化为更高的端到端问答准确率,突显了上游检索的重要性。
为了学习DPR嵌入,他们在现有的问题-答案对上对两个独立的基于BERT的编码器进行了微调。段落编码器()将文本段落嵌入向量中,而查询编码器()将问题嵌入向量中。然后使用查询嵌入来检索与问题最接近的段落。
他们训练了编码器,使得点积相似度成为一个良好的排序函数,并将损失函数优化为正向段落的负对数似然。DPR嵌入是为了最大化问题和相关段落向量之间的内积而进行优化的。目标是学习一个向量空间,使得问题和相关段落的配对能够紧密地靠在一起。
对于推理,他们通过将所有段落嵌入并在离线状态下对其进行索引。然后,在查询时给定一个问题,他们通过计算问题的嵌入,通过近似最近邻检索获取前个段落,并将其提供给语言模型(BERT),该模型输出问题的答案。
为了解决这些缺点,他们引入了RAG(也称为半参数模型)。密集向量检索作为非参数组件,而预训练的LLM则作为参数组件。他们重新使用了DPR编码器来初始化检索器并构建文档索引。对于LLM,他们使用了BART,一个拥有4亿参数的seq2seq模型。

检索增强生成概述
在推理过程中,他们将输入与检索到的文档连接起来。然后,LLM根据原始输入、检索到的文档和先前的令牌生成。对于生成,他们提出了两种方法,这两种方法在使用检索到的段落生成输出时有所不同。
在第一种方法中,RAG-Sequence模型使用相同的文档来生成完整的序列。因此,对于检索到的文档,生成器会为每个文档生成一个输出。然后,将每个输出序列的概率进行边际化处理(将在中的每个输出序列的概率相加,并乘以每个文档被检索到的概率)。最后,选择具有最高概率的输出序列。
另一方面,RAG-Token可以根据不同的文档生成每个令牌。给定检索到的文档,生成器会为每个文档的下一个输出令牌产生一个分布,然后进行边际化(聚合所有个体令牌分布)。然后,该过程会为下一个令牌重复进行。这意味着,对于每个令牌生成,它可以根据原始输入和先前生成的令牌检索到不同的相关文档集合。因此,文档可以具有不同的检索概率,并对下一个生成的令牌产生不同的贡献。
Fusion-in-Decoder(FiD)还使用生成模型进行开放领域问答的检索。它支持两种检索方法,BM25(使用默认参数的Lucene)和DPR。FiD之所以被称为融合在解码器中的原因,是因为它仅在解码器中对检索到的文档进行融合。

Fusion-in-Decoder概述
因为它在编码器中独立处理段落,所以它可以扩展到大量的段落,因为它只需要一次性对一个上下文进行自注意力处理。因此,计算量随着检索到的段落数量的增加呈线性增长(而不是二次增长),使其比RAG-Token等替代方案更具可扩展性。然后,在解码过程中,解码器联合处理编码的段落,使其能够更好地整合多个检索到的段落的上下文。
检索增强变压器(RETRO)采用了类似的模式,其中结合了一个冻结的BERT检索器、一个可微分的编码器和分块交叉注意力来生成输出。不同的是,RETRO在整个预训练阶段都进行检索,而不仅仅是在推理过程中。此外,它们根据输入的片段提取相关文档。这样可以在生成过程中进行更精细、重复的检索,而不仅仅是每次查询只检索一次。

RETRO概述
在检索过程中,RETRO将输入序列分成64个标记的块。然后,它找到与前一个块相似的文本,为当前块提供上下文。检索索引由两个连续的标记块和组成。前者是邻近块(64个标记),用于计算关键字,而后者是原始文档中的连续块(64个标记)。
检索基于BERT嵌入的近似最近邻(通过欧几里得距离)。(有趣的离开了通常的余弦或点积相似度。)建立在SCaNN上的检索索引可以在10毫秒内查询一个包含2T个标记的数据库。
他们还演示了如何对现有的基准模型进行改进。通过冻结预训练权重,只训练分块交叉注意力和邻居编码器参数(7B模型权重的不到10%),他们可以在只需要600万个训练序列(预训练序列的3%)的情况下增强transformers的检索能力。经过改装的模型能够超越基准模型的性能,并且达到了接近从头开始训练的改装模型的性能水平。
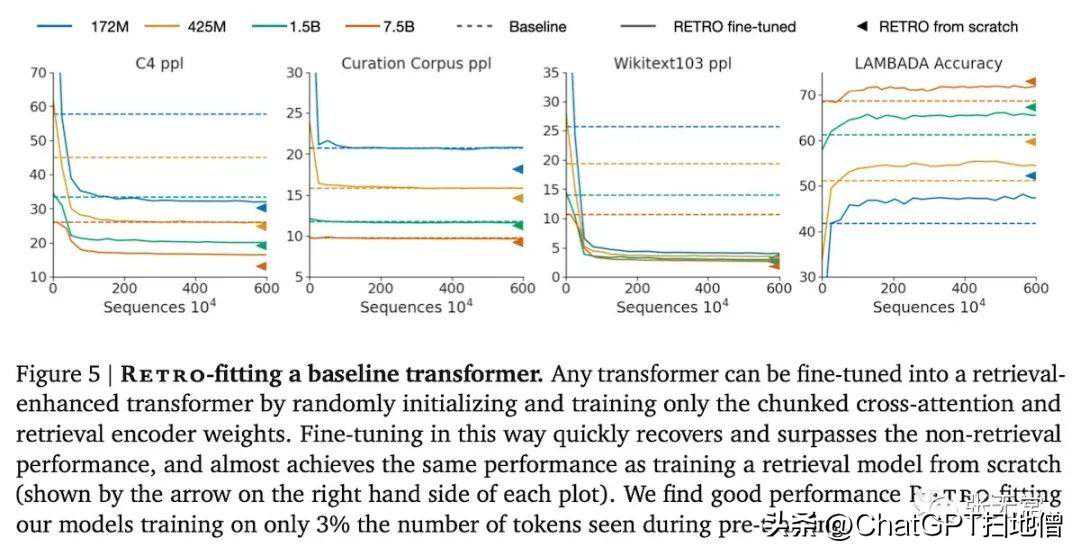
从对预训练模型进行RETRO适配的性能
互联网增强的语言模型提议使用一个普通的“现成”搜索引擎来增强语言模型。首先,它们通过谷歌搜索检索一组相关文档。由于这些检索到的文档往往很长(平均长度为2,056个词),它们将其分成每段六个句子的段落。最后,他们通过TF-IDF嵌入问题和段落,并应用余弦相似度来对每个查询的最相关段落进行排名。

互联网增强的LLM概述
通过少量提示来调整LLM的检索段落。它们采用传统的-shot提示()用于闭卷问答(仅限问题和答案),并通过添加证据段落来扩展它,使得每个上下文都包含证据、问题和答案。
对于生成器,他们使用了Gopher,一个训练了300B个标记的280B参数模型。对于每个问题,他们基于50个检索到的段落生成了四个候选答案。最后,他们通过多种方法,包括直接推理、RAG、噪声通道推理和专家乘积(PoE),通过估计答案概率来选择最佳答案。PoE一直表现最好。
RAG也被应用于非QA任务,如代码生成。虽然CodeT5+可以作为独立的生成器使用,但与RAG结合使用时,在代码生成方面明显优于类似模型。
为了评估RAG对代码生成的影响,他们在三个场景中对模型进行了评估:
检索式:将排名第一的代码示例作为预测结果
仅生成式:仅基于解码器输出代码
检索增强:在通过解码器生成代码之前,将最佳代码示例附加到编码器输入中。

CodeT5+的RAG概述
作为一个定性的例子,他们展示了检索到的代码提供了关键的上下文(例如,使用urllib3来表示HTTP请求),并且指导生成过程朝着更正确的预测方向发展。相比之下,仅生成的方法返回的输出是不正确的,只捕捉到了“下载”和“压缩”的概念。
如果我们没有查询-段落对的相关性判断,那该怎么办呢?没有这些判断,我们将无法训练将查询和文档嵌入到同一嵌入空间中的双编码器,其中相关性由内积表示。假设性文档嵌入(HyDE)提供了一种解决方案。

HyDE的概述
给定一个查询,HyDE首先提示一个LLM,比如InstructGPT,生成一个假设文档。然后,一个无监督编码器,比如Contriver,将文档编码成嵌入向量。最后,计算假设文档和语料库之间的内积,并检索出最相似的真实文档。
期望是编码器的密集瓶颈充当有损压缩器,并通过嵌入排除多余的非事实细节。这将将相关性建模问题从表示学习任务转变为生成任务。
如何申请RAG根据我使用Obsidian-copilot的经验,我发现混合检索(传统搜索索引+基于嵌入的搜索)比单独使用任何一种方法都更有效。在那个项目中,我将经典检索(通过OpenSearch的BM25)与语义搜索相结合(e5-small-v2)。
为什么不仅使用基于嵌入的搜索呢?虽然在许多情况下它非常出色,但也存在一些无法满足的情况,比如:
搜索一个人或物体的名字(例如,尤金,)
搜索缩写词或短语(例如,RAG,RLHF)
搜索ID(例如,,)
但是关键词搜索也有其局限性。它只模拟简单的词频,并不能捕捉语义或相关信息。因此,它无法很好地处理同义词或上位词(即代表一般化的词)。这就是将其与语义搜索结合起来的地方是互补的。
此外,使用传统的搜索索引,我们可以利用元数据来优化结果。例如,我们可以使用日期过滤器来优先显示较新的文档,或者将搜索范围缩小到特定的时间段。如果搜索与电子商务有关,平均评分或类别的筛选是有帮助的。拥有元数据对于下游排名也很方便,比如优先考虑被引用更多的文档,或者通过销售量提升产品。
关于嵌入(embeddings),看起来流行的方法是使用text-embedding-ada-002。它的好处包括通过API的简便使用,不需要维护自己的嵌入基础设施或自主托管嵌入模型。然而,经验和轶事表明它在检索方面并不那么好。
OG嵌入方法包括Word2vec和fastText。FastText是一个开源的轻量级库,可以让用户利用预训练的嵌入或训练新的嵌入模型。它提供了157种语言的预训练嵌入,并且即使没有GPU,速度也非常快。这是我在初期概念验证阶段的首选。
另一个很好的基准是句子转换器。它可以轻松计算句子、段落甚至图像的嵌入。它基于BERT和RoBERTa等可靠的转换器,并支持100多种语言。
最近,教师模型展示了最先进的性能。在训练过程中,这些模型将任务描述添加到文本之前。然后,在嵌入新文本时,我们只需描述任务即可获得特定任务的嵌入。(在我看来,这与调整嵌入模型的指令并没有太大区别。)
以E5系列为例。对于开放式问答和信息检索,我们只需在索引中的文档前加上passage:,并在查询前加上query:。如果任务是对称的(例如语义相似性、释义检索),或者我们想要将嵌入作为特征使用(例如分类、聚类),我们只需使用query:前缀即可。
Instructor模型更进一步,允许用户自定义前置提示:“代表domaintask_typetask_objective的:”。例如,“代表检索的维基百科文档:”。(域和任务目标是可选的)。这将提示调整的概念引入了文本嵌入领域。
截至8月1日,MTEB排行榜上排名第一的嵌入模型是阿里巴巴达摩院的GTE系列模型。最佳表现的模型大小仅为下一款模型的一半(0.67GB对比1.34GB)。第二名是gte-base,模型大小仅为0.22GB,嵌入维度为768。(感谢Nirant提供信息。)
为了在大规模情况下以低延迟检索文档,我们使用近似最近邻(ANN)算法。它优化了检索速度,并返回近似(而非精确)的前个最相似的邻居,以少许准确度损失换取大幅加速。
ANN嵌入索引是一种数据结构,可以高效地进行ANN搜索。在高层次上,它们在嵌入空间上构建分区,以便我们可以快速定位查询向量所在的特定空间。一些流行的技术包括:
局部敏感哈希(LSH):核心思想是创建哈希函数,使得相似的项有可能落入同一个哈希桶中。通过只需要检查相关的桶,我们可以高效地执行最近邻查询。
FacebookAI相似性搜索(FAISS):它使用量化和索引的组合来实现高效的检索,支持CPU和GPU,并且由于其对内存的高效利用,可以处理数十亿个向量。
分层可导航小世界(HNSW):受到“六度分隔”的启发,它构建了一个体现小世界现象的分层图结构。在这里,大多数节点可以通过最少的跳数从任何其他节点到达。这种结构允许HNSW从更广泛、更粗糙的近似开始查询,并逐渐在较低层次上缩小搜索范围。
可扩展最近邻居(ScaNN):ANN通过两个步骤完成。首先,粗粒度量化减少了搜索空间。然后,在减少的集合内进行细粒度搜索。这是我见过的最佳召回率/延迟权衡。
在评估ANN指数时,需要考虑一些因素,包括:
回忆:它在与精确最近邻的比较中表现如何?
延迟/吞吐量:每秒可以处理多少个查询?
内存占用:为了提供索引需要多少RAM?
添加新项目的便利性:是否可以在不重新索引所有文档(LSH)或需要重建索引(ScaNN)的情况下添加新项目?
没有一个框架在每个方面都比其他框架更好。因此,在进行基准测试之前,首先要定义您的功能和非功能需求。就个人而言,我发现ScaNN在召回率和延迟之间的权衡方面表现出色(请参见此处的基准测试图表)。
三、微调:为了在特定任务上变得更好
微调是指对预训练模型(已经通过大量数据进行训练)进行进一步优化,以适应特定任务。目的是利用模型在预训练过程中已经获得的知识,并将其应用于特定任务,通常涉及较小的、任务特定的数据集。
“微调”这个术语非常广泛,可以涉及到几个概念,比如:
继续预训练:使用特定领域的数据,在基础模型上应用相同的预训练方案(下一个标记预测,掩码语言建模)。
指令微调:预训练(基础)模型通过指令-输出对的示例进行微调,以遵循指令、回答问题、成为“waifu”等。
单任务微调:预训练模型专注于狭窄而具体的任务,如毒性检测或摘要生成,类似于BERT和T5。
为什么要进行微调?对开放式LLM进行微调,正变得越来越可行,这是因为有几个原因,可以作为使用第三方云端LLM的替代选择。
性能和控制:微调可以提高现成基础模型的性能,甚至可能超过第三方LLM。它还可以更好地控制LLM的行为,从而实现更强大的系统或产品。总的来说,微调使我们能够构建与仅仅使用第三方或开放的LLM有所区别的产品。
模块化:单任务微调使我们能够使用一支由多个较小模型组成的团队,每个模型都专注于自己的任务。通过这种设置,系统可以被模块化为用于内容审核、提取、摘要等任务的个别模型。另外,考虑到每个模型只需专注于一小部分任务,对于对齐税的担忧也减少了,即在一个任务上微调模型会降低其他任务的性能。
减少依赖:通过对模型进行微调和自行托管,我们可以减少对专有数据(例如个人身份信息、内部文件和代码)暴露给外部API的法律担忧。它还可以避免第三方LLM(语言模型)带来的限制,如速率限制、高成本或过于严格的安全过滤器。通过对自己的LLM进行微调和托管,我们可以确保数据不离开我们的网络,并根据需要扩展吞吐量。
更多关于微调的内容为什么我们需要对基础模型进行微调?冒昧地说,基础模型主要是针对其训练语料库来预测下一个词。因此,它们并不擅长遵循指令或回答问题。当被问到问题时,他们往往会用更多的问题来回应。因此,我们进行指令微调,让他们学会适当地回应。
然而,微调并非没有挑战。首先,我们需要大量的演示数据。例如,在InstructGPT论文中,他们使用了13k个指令-输出样本进行监督微调,33k个输出比较用于奖励建模,以及31k个没有人工标签的提示作为RLHF的输入。
此外,微调还伴随着一种对齐成本——该过程可能导致某些关键任务的性能下降。(毕竟,没有免费的午餐。)同一篇InstructGPT论文发现,相对于GPT-3基础模型,RLHF在公共NLP任务(如SQuAD、HellaSwag和WMT2015法英翻译)上导致了性能回归。(一种解决方法是拥有几个较小的、专门擅长狭窄任务的模型。)
Fine-tuning与迁移学习的概念相似。根据维基百科的定义:“迁移学习是一种机器学习技术,通过重复利用从一个任务中学到的知识来提升在相关任务上的性能。”几年前,迁移学习使我能够轻松地应用在ImageNet上训练的ResNet模型来对时尚产品进行分类,并构建图像搜索。
ULMFit是早期将迁移学习应用于文本的论文之一。他们建立了自我监督预训练(在无标签数据上)后跟微调(在有标签数据上)的协议。他们使用了AWS-LSTM,这是一种带有不同门的LSTM变体。

ULMFit概述
在预训练阶段(下一个词预测),模型使用包含28.6个维基百科文章和103M个单词的wikitext-103进行训练。然后,在目标任务微调阶段,语言模型会使用特定任务领域的数据进行微调。最后,在分类器微调期间,模型会增加两个额外的线性块,并在目标分类任务上进行微调,其中包括情感分析、问题分类和主题分类。
从那时起,预训练加微调的模式在语言建模方面取得了很大进展。双向编码器表示转换(BERT;仅编码器)通过对英文维基百科和BooksCorpus进行掩码语言建模和下一句预测进行了预训练。然后,它在特定任务的输入和标签上进行了微调,包括单句分类、句对分类、单句标记和问答。

BERT概述
生成式预训练转换器(GPT;仅解码器)首先通过下一个标记预测在BooksCorpus上进行预训练。然后进行了单任务微调,用于文本分类、文本蕴含、相似度和问答等任务。有趣的是,他们发现将语言建模作为辅助目标加入后,模型在训练过程中更好地泛化和更快地收敛。

GPT概述
文本到文本转换变压器(T5;编码器-解码器)在ColossalCleanCrawledCorpus(C4)上进行了预训练,这是CommonCrawl2019年4月的清理版本。它采用了与BERT相同的去噪目标,即掩码语言建模。然后对文本分类、摘要生成、问答和机器翻译等任务进行了微调。

T5概述
但与ULMFIt、BERT和GPT不同的是,T5仅使用了文本到文本的方式来表示下游任务,而不是使用不同的分类器头部。例如,翻译任务的输入文本以TranslationEnglishtoGerman:开头,而摘要任务可能以Summarize:或TL;DR:开头。这个前缀本质上成为了一个超参数(首次出现的提示工程实例?)。这种设计选择使他们能够在各种下游任务中使用单个经过微调的模型。
InstructGPT将单任务微调的理念扩展到了指令微调。基础模型是GPT-3,在互联网数据(包括CommonCrawl、WebText、图书和维基百科)上进行了预训练。然后,它对期望行为的示范进行了监督微调(指令和输出)。接下来,它在比较数据集上训练了一个奖励模型。最后,它通过PPO对指导模型进行了优化,以适应奖励模型,这最后阶段更注重对齐而不是特定任务的表现。
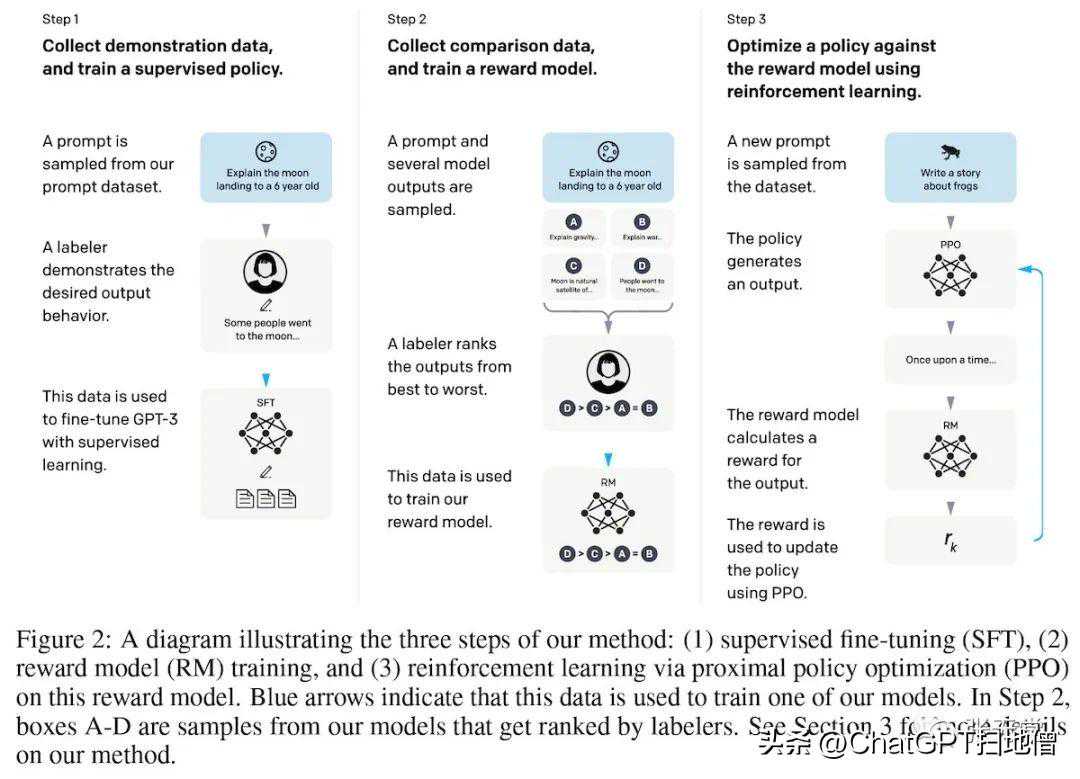
InstructGPT的微调步骤概述
接下来,让我们从精调模型转向精调技术。
软提示调整将一个可训练的张量添加到模型的输入嵌入中,从根本上创建了一个软提示。与离散的文本提示不同,软提示可以通过反向传播进行学习,这意味着它们可以进行微调,以融入任意数量的标记示例的信号。
接下来是前缀调整。与其向模型输入添加一个软提示,它会在所有Transformer块的隐藏状态之前添加可训练的参数。在微调过程中,语言模型的原始参数保持冻结状态,而前缀参数则会被更新。

前缀调整概述
这篇论文表明,尽管只需要对0.1%的参数进行更新,但其实现的性能与完全微调相当。此外,在数据有限且对新主题进行外推的情况下,它的表现优于完全微调。一个假设是,涉及的参数越少,有助于减少对较小目标数据集的过拟合现象。
还有适配器技术。该方法在每个Transformer块之后,注意力层和前馈网络层之后,分别添加了两个全连接网络层。在GLUE上,只需为每个任务增加3.6%的参数,就能够达到全面微调性能的0.4%。

适配器概述
低秩适应(LoRA)是一种技术,其中适配器被设计为两个低秩矩阵的乘积。它受到Aghajanyan等人的启发,他们表明,当适应特定任务时,预训练语言模型具有低内在维度,并且尽管在较小的子空间中进行随机投影,仍然可以高效地学习。因此,他们假设在适应过程中的权重更新也具有较低的内在等级。

LoRA概述
与前缀调整类似,他们发现LoRA在性能上优于包括完全微调在内的几个基准模型。再次,假设是LoRA由于其降低的秩提供了隐式正则化。相比之下,全面微调会更新所有权重,可能容易过拟合。
QLoRA基于LoRA的思想。但是在微调过程中,它使用了4位量化模型,而不是完整的16位模型。它引入了几项创新,例如4位NormalFloat(用于量化模型),双量化(以节省额外的内存),以及分页优化器(在GPU内存不足时将数据传输到CPURAM以防止OOM错误)。

QLoRA概述
因此,QLoRA将对一个65B模型进行微调所需的平均内存要求从超过780GB减少到了更易管理的48B,而且与16位完全微调的基准相比,不会降低运行时间或预测性能。
有趣的事实:在与TimDettmers的聚会中,他开玩笑说双重量化是“有点愚蠢的想法,但完美地发挥作用。”嘿,如果它有效,那就好。
如何进行微调申请?第一步是收集示范数据/标签。这些可以是简单的任务,比如文档分类、实体提取或摘要,也可以是更复杂的问题,比如问答或对话。收集这些数据的一些方法包括:
通过专家或众包人工标注员:虽然这种方式费时费力,但通常能够产生具有良好指导方针的高质量数据。
查询具有宽松许可证的更大型开放模型:通过适当的工程技术,我们可能能够从一个更大的模型(Falcon40BInstruct)中获取合理的演示数据,用于对较小的模型进行微调。
重复使用开源数据:如果您的任务可以被定义为自然语言推理(NLI)任务,我们可以使用MNLI数据来微调模型以执行NLI。然后,我们可以继续在内部数据上微调模型,将输入分类为蕴含、中性或矛盾。
注意:某些LLM术语禁止用户使用其输出来训练其他模型。
OpenAI使用条款(第2c条,第iii款):您不得使用服务的输出来开发与OpenAI竞争的模型。
LLaMA2社区许可协议(第1b-v条):您不得使用Llama材料或Llama材料的任何输出或结果来改进任何其他大型语言模型(不包括Llama2或其衍生作品)。
下一步是定义评估指标。我们在之前的部分已经讨论过这个问题。然后,选择一个预训练模型。有几个开源的预训练模型可供选择,许可证也很宽松。除了Llama2(因为它不完全商业使用)之外,Falcon-40B被认为是表现最好的模型。尽管如此,我发现它在生产环境中调优和服务起来非常笨重。
相反,我倾向于使用像Falcon-7B这样的较小型号。如果我们能够简化并更加明确地界定任务,BERT、RoBERTA和BART是分类和自然语言推理任务的可靠选择。除此之外,Flan-T5是翻译、摘要、标题生成等方面的可靠基准。
我们可能还需要更新模型架构。当预训练模型的架构与任务不符时,这是必要的。例如,我们可能需要更新BERT或T5上的分类头以适应我们的任务。提示:如果任务是一个简单的二分类任务,NLI模型可以直接使用。蕴含被映射为正面,矛盾被映射为负面,而神经标签可以表示不确定性。
然后,选择一种精调方法。LoRA和QLoRA是一个不错的起点。但是,如果你的精调更加深入,比如在新的领域知识上进行持续的预训练,你可能会发现需要进行完全的精调。
四、缓存:为了减少延迟和成本缓存是一种技术,用于存储先前检索或计算过的数据。这样,将来对相同数据的请求可以更快地提供服务。在为LLM世代提供服务的过程中,流行的方法是将LLM响应缓存,并以输入请求的嵌入为键。然后,对于每个新的请求,如果接收到一个语义上相似的请求,我们可以提供缓存的响应。对于一些从业者来说,这听起来就像是“一场等待发生的灾难”。我倾向于同意这种观点。因此,我认为采用这种模式的关键是要找出如何安全地进行缓存,而不仅仅依赖语义相似性。
为什么要使用缓存?缓存可以显著减少之前已经提供过的响应的延迟。此外,通过消除对相同输入再次计算响应的需求,我们可以减少LLM请求的数量,从而节省成本。此外,还有一些使用情况不支持以秒为单位的延迟。因此,预先计算和缓存可能是满足这些使用情况的唯一方式。
关于缓存的更多信息缓存是一个高速存储层,用于存储经常访问的数据子集。这样,我们可以通过缓存而不是数据的主要存储(例如搜索索引、关系数据库)更快地响应这些请求。总的来说,缓存使得之前获取或计算的数据能够高效地被重复使用。(更多关于缓存和最佳实践的内容。)
LLMs的缓存示例是GPTCache。

GPTCache概述
当收到新的请求时:
嵌入生成器:通过各种模型(如OpenAI的text-embedding-ada-002,FastText,句子转换器等)嵌入请求。
相似度评估器:通过向量存储计算请求的相似度,然后提供一个距离度量。向量存储可以是本地的(FAISS,Hnswlib)或基于云的。它还可以通过模型计算相似度。
缓存存储:如果请求相似,则获取并提供缓存的响应。
LLM:如果请求不够相似,它将传递给LLM,然后生成结果。最后,响应被提供并缓存以供将来使用。
Redis也分享了一个类似的例子。有些团队甚至会预先计算他们预计会收到的所有查询。然后,他们设置了一个相似度阈值,用于确定哪些查询足够相似,值得缓存响应。
如何应用缓存?我们应该从对用户请求模式有一个良好的理解开始。这样可以让我们有计划地设计缓存,以便能够可靠地应用。
首先,让我们考虑一个非LLM的例子。想象一下,我们正在为一个电子商务网站缓存产品价格。在结账过程中,显示(可能过时的)缓存价格是否安全?可能不会,因为客户在结账时看到的价格应该与他们最终被收取的金额相同。在这里使用缓存是不合适的,因为我们需要确保对客户的一致性。
现在,回到LLM的回应。想象一下,我们收到了一个关于《碟中谍2》的摘要请求,它在语义上与《碟中谍3》足够相似。如果我们根据语义相似性来查找缓存,可能会提供错误的回应。
我们还需要考虑缓存对使用模式的有效性。一种量化的方法是通过缓存命中率(直接从缓存中提供服务的请求的百分比)。如果使用模式是均匀随机的,缓存需要频繁更新。因此,努力保持缓存的最新状态可能会抵消缓存所带来的任何好处。另一方面,如果使用遵循幂律分布,其中少部分独特请求占据了大部分流量(例如搜索查询、产品浏览),那么缓存可能是一种有效的策略。
除了语义相似性之外,我们还可以基于以下内容进行缓存探索:
项目ID的配对:例如当我们在两部电影之间进行比较时。虽然这看起来是,但实际上,只有少数几种组合驱动了大部分的流量,比如三部曲中的电影之间的比较。
受限输入:例如电影类型、导演或主演等变量。例如,如果用户想要从特定导演那里获得电影推荐,我们可以执行结构化查询,并通过LLM运行它,以更优雅地构建回复。另一个例子是基于下拉选项生成代码——如果代码已经经过验证可以正常工作,我们可以将其缓存以便可靠地重复使用。
此外,缓存不仅仅需要即时发生。正如Redis所分享的,我们可以在提供服务之前离线或异步地预先计算LLM生成。通过从缓存中提供服务,我们将延迟从生成(通常为几秒钟)转移到缓存查找(毫秒级)。批量预计算还可以帮助降低与实时服务相比的成本。
虽然这里列出的方法可能没有自然语言输入的语义缓存那样灵活,但我认为它在效率和可靠性之间提供了一个良好的平衡。
五、护栏:确保产出质量在LLMs的背景下,防护栏验证LLMs的输出,确保输出不仅听起来好,而且在语法上是正确的、事实准确的,并且没有有害内容。它还包括防范对抗性输入。为什么需要护栏?他们确保模型输出足够可靠和一致,以便在生产中使用。例如,我们可能要求输出采用特定的JSON模式,以便机器能够读取,或者我们需要生成的代码可执行。护栏可以帮助进行语法验证。
它们还提供了额外的安全层,并对LLM的输出进行质量控制。例如,为了验证生成的内容是否适合提供,我们可能希望检查输出是否有害,验证其事实准确性,或确保与提供的上下文一致。
更多关于护栏的信息一种方法是通过提示来控制模型的回应。例如,Anthropic分享了关于设计提示以引导模型生成有帮助、无害和诚实(HHH)回应的信息。他们发现,使用HHH提示进行Python微调相比使用RLHF微调可以获得更好的性能。

HHH提示示例
一种更常见的方法是验证输出。一个例子是Guardrails包。它允许用户通过Pydantic风格的验证在LLM输出上添加结构、类型和质量要求。如果检查失败,它可以触发纠正措施,比如对有问题的输出进行过滤或重新生成另一个响应。
大部分的验证逻辑都在中。看到它们是如何实现的确实很有趣。总体来说,这些防护措施可以分为以下几类:
单一输出值验证:这包括确保输出(i)是预定义选项之一,(ii)长度在一定范围内,(iii)如果是数字,落在预期范围内,以及(iv)是一个完整的句子。
语法检查:这包括确保生成的URL有效且可访问,以及Python和SQL代码没有错误。
语义检查:这个步骤验证输出是否与参考文档一致,或者提取的摘要是否与源文档相似。可以通过余弦相似度或模糊匹配技术来进行这些检查。
安全检查:这确保生成的输出没有不适当的语言,或者翻译文本的质量很高。
因此,NeMo的方法有些不同:不是使用更确定性的检查,比如验证一个值是否存在于列表中或检查代码中的错误,NeMo更倾向于使用另一个LLM来验证输出(受SelfCheckGPT的启发)。
在他们的事实核查和幻觉预防示例中,他们要求LLM本身检查最新的输出是否与给定的上下文一致。为了事实核查,如果从知识库中检索到的文件证实回答是正确的,就会查询LLM。为了防止产生幻觉,由于没有可用的知识库,他们让LLM生成多个替代完成,作为上下文。基本假设是,如果LLM生成的多个补全结果彼此不一致,那么原始的补全结果很可能是一种幻觉。
审查示例遵循简单的方法:通过LLM对回复进行筛查,以检测有害和不道德的内容。鉴于伦理和有害内容的微妙之处,启发式和传统机器学习技术无法胜任。因此,深入理解对话的意图和结构需要一个LLM学位。
除了使用护栏来验证LLM的输出之外,我们还可以直接引导输出以符合特定的语法。一个例子是微软的Guidance。与通过提示强制使用JSON模式的Guardrails不同,Guidance通过注入构成结构的标记来强制执行模式。
我们可以将Guidance视为LLM交互和输出的领域特定语言。它借鉴了Handlebars的灵感,Handlebars是一种在Web应用程序中广泛使用的模板语言,使用户能够执行变量插值和逻辑控制。
然而,Guidance通过线性执行与常规的模板语言有所区别。这意味着它保持生成的令牌的顺序。因此,通过插入作为结构一部分的令牌,而不是依赖于LLM正确生成它们,Guidance可以指定特定的输出格式。在他们的示例中,他们展示了如何生成始终有效的JSON,生成具有多个键的复杂输出格式,确保LLM扮演正确的角色,并使代理之间相互交互。
他们还引入了一个叫做“tokenhealing”的概念,这是一个有用的功能,可以帮助我们避免由于标记化而产生的微妙错误。简单来说,它会将生成的过程回退一个标记,直到提示的结尾,然后限制第一个生成的标记与提示中的最后一个标记匹配的前缀。在制作提示时,这消除了对令牌边界的担忧。
如何安装护栏?尽管在工业领域中,防护栏的概念仍然处于初级阶段,但我们可以考虑一些立即可用且实用的策略。
结构指导:尽可能应用指导。它能直接控制输出,并提供更精确的方法,以确保输出符合特定的结构或格式。
句法保护措施:这些包括检查分类输出是否在一组可接受的选择范围内,或者数值输出是否在预期范围内。此外,如果我们生成SQL语句,这些措施可以验证其正确性,并确保查询中的所有列与模式匹配。对于Python代码也是如此。
内容安全护栏:这些验证输出是否含有有害或不适当的内容。可以简单地检查是否包含脏话、淫秽话语或其他不良词汇,也可以使用亵渎检测模型。(通常会对输出进行审查分类器的运行。)更复杂和细致的输出可以依赖于LLM评估器。
语义/事实性保障:这些保证输出与输入在语义上相关。假设我们根据电影的简介生成一个关于该电影的两句摘要。我们可以验证生成的摘要是否在语义上与输出相似,或者让另一个LLM确认摘要是否准确地代表了提供的概要。
输入保护措施:这些限制了模型会响应的输入类型,有助于减轻模型对不适当或对抗性提示的响应风险,从而避免生成有害内容。例如,如果您要求Midjourney生成不适宜内容,您将收到错误提示。这可以很直接地通过与字符串列表进行比较或使用一个审查分类器来实现。
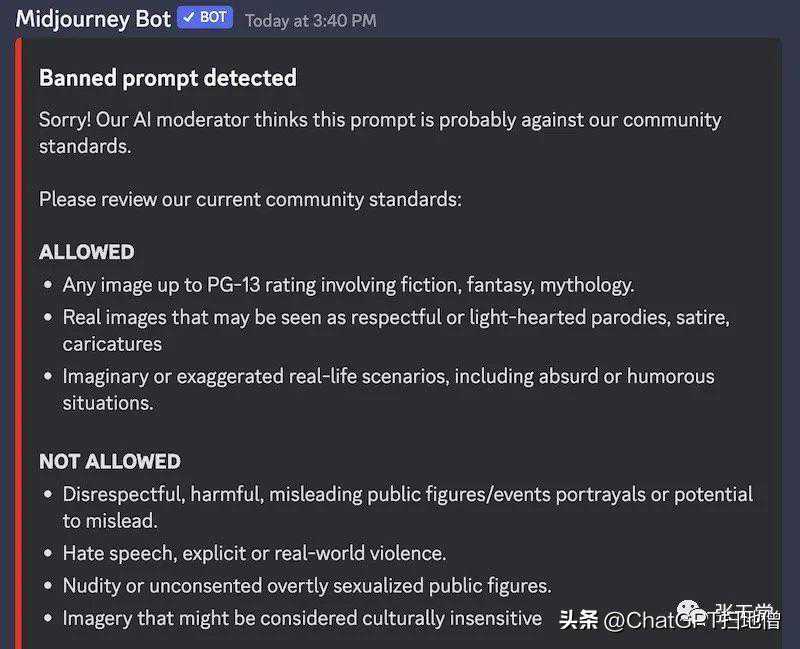
中途旅程上的输入护栏示例
六、防御性用户体验:预测并优雅地处理错误防御性用户体验(DefensiveUX)是一种设计策略,它承认在用户与基于机器学习或LLM的产品进行交互时,可能会发生不准确或产生幻觉等不良情况。因此,目的是提前预测和管理这些问题,主要通过引导用户行为、防止滥用和优雅地处理错误来实现。为什么要进行防御性用户体验设计?机器学习和LLM并不完美,它们可能会产生不准确的输出。此外,它们对相同的输入会随时间而有不同的响应,比如搜索引擎因个性化而显示不同的结果,或者LLM在更具创造性的设置下生成多样化的输出。这可能违反了一致性原则,该原则主张保持一致的用户界面和可预测的行为。
防御性用户体验可以通过提供以下内容来缓解上述问题:
提高可访问性:通过帮助用户了解机器学习/语言模型功能的工作原理和限制,防御性用户体验使其更易于访问和用户友好。
增加信任:当用户看到该功能能够优雅地处理困难情况并且不会产生有害输出时,他们很可能会更加信任它。
更好的用户体验:通过设计模型和用户体验来处理模糊的情况和错误,防御性用户体验为更流畅、更愉悦的用户体验铺平了道路。
关于防御性用户体验的更多内容要了解更多关于防御性用户体验(DefensiveUX)的内容,我们可以参考微软、谷歌和苹果的人工智能(AI)准则。
这些准则遵循一定的风格:每个准则都是一个简洁的行动规则,由3-10个词组成,以动词开头。每个规则都附有一句话,解决潜在的歧义。它们根据在用户互动过程中可能的应用进行组织。
最初:明确系统能做什么(G1),明确系统在能做的事情上表现如何出色(G2)
在互动过程中:基于上下文的时间服务(G3),减轻社会偏见(G6)
当错误时:支持高效解雇(G8),支持高效纠正(G9)
随着时间的推移:从用户行为中学习(G13),提供全局控制(G17)
谷歌的“人工智能指南”根植于谷歌产品团队和学术研究所得到的数据和见解。与微软的指南以用户为中心不同,谷歌将其指南组织成开发者需要牢记的概念。
有23个模式围绕产品开发过程中常见的问题进行分组,包括:
如何开始人性化的人工智能:确定人工智能是否增加价值,及早投资于良好的数据实践(例如,评估)。
如何引导用户使用新的人工智能功能:确保探索安全,以熟悉为基础,分阶段自动化
如何帮助用户对我的产品建立信任:设定正确的期望,保持透明度,在风险较低时自动化更多。
该文档着重讨论如何将苹果的设计原则应用于融入机器学习的产品中,强调界面设计的方面,而非模型功能。它首先要求开发者考虑机器学习在他们的应用中的作用,并从用户体验出发进行反向思考。这包括诸如机器学习是否:
关键或互补:例如,FaceID无法在没有机器学习的情况下工作,但键盘仍然可以在没有快速输入的情况下工作。
主动还是被动:Siri建议是主动的,而自动更正是被动的。
动态或静态:推荐是动态的,而照片中的物体检测只会随着每个iOS版本的发布而改进。
如何应用防御性用户体验?根据上述指南,这里有一些基于这些指南的模式。(免责声明:我不是设计师。)
设定正确的期望。这个原则在所有三个指南中都是一致的:
微软:明确系统能够做到什么程度(帮助用户了解人工智能系统可能犯错的频率)
Google:设定正确的期望(对用户透明地说明您的AI驱动产品能做什么,不能做什么)
苹果:帮助人们树立现实的期望(在营销材料或功能的背景下描述限制)

谷歌Bard搜索结果的免责声明示例(注意:nrows不是有效的参数。)
通过对我们产品的功能和输出能力进行透明化,我们帮助用户调整他们对其功能和输出的期望。虽然这可能会导致用户在短期内对其信任度降低,但从长远来看,这有助于培养信任感——用户不太可能高估我们的产品,从而避免失望。
提供高效的解雇功能。这明确地被列为微软的第8条准则:支持高效的解雇(使解雇或忽略不需要的AI系统服务变得容易)。
例如,如果用户在浏览我们的网站时,弹出一个聊天机器人询问他们是否需要帮助,用户应该很容易地关闭聊天机器人。这样可以确保聊天机器人不会妨碍用户,尤其是在屏幕较小的设备上。同样,GitHubCopilot允许用户通过继续输入来方便地忽略其代码建议。虽然这可能会在短期内减少人工智能功能的使用,但它可以防止其在长期内变得烦扰,并潜在地降低客户满意度。
提供归属。这在所有三个指南中都有列出。
微软:明确解释系统为何做出某种行为(使用户能够访问解释为何AI系统表现如此的说明)
苹果:考虑使用归因来帮助人们区分结果
专家和社区的背景也增强了用户的信任。例如,如果用户正在寻找徒步旅行的建议,提到一个被相关社区高度推荐的徒步路线会起到很大的作用。它不仅为推荐增添了价值,还通过人际关系帮助用户校准信任。

社交证明的例子
最后,苹果的指南中包括一些常见的描述,比如“因为你读过非小说类书籍”,“你读过的作者的新书”。这些描述不仅个性化了用户体验,还提供了背景信息,增强了用户的理解和信任。
以熟悉为基础。当向用户介绍新的人工智能产品或功能时,通过熟悉的用户体验模式和特性来引导他们会有所帮助。这样可以让用户更容易专注于主要任务,并开始对我们的新产品建立信任。抵制通过奇特的用户界面元素展示新的和“神奇”的功能的诱惑。
因此,尽管聊天提供了更多的灵活性,但也需要用户付出更多的努力。此外,使用聊天框不够直观,因为它缺乏关于用户如何调整输出的指示符。总的来说,我认为坚持使用熟悉且受限的用户界面可以让用户更容易地浏览我们的产品;聊天只应被视为次要或第三选择。
为什么收集用户反馈如何收集用户反馈Apple:提供可供您的应用程序使用的可操作信息,以改善其向用户呈现的内容和体验

聊天机器人,如ChatGPT和BingChat,就是一个例子。随着时间的推移,日常使用情况发生了怎样的变化?如果产品具有粘性,这意味着用户喜欢它。另外,平均对话持续多长时间?这个问题很棘手:长时间的对话是否更好,因为对话内容有趣且富有成果?还是更糟糕,因为用户花费更长的时间才能得到他们所需的信息?
机器学习中常见的其他模式除了我们已经探讨过的七种模式之外,还有几种机器学习中的其他模式也与LLM系统和产品相关。它们包括:
数据飞轮:持续的数据收集改进模型,提供更好的用户体验。反过来,这促进了更多的使用,为进一步评估和优化模型提供了更多的数据,形成了一个良性循环。
级联:与其将一个复杂的任务交给LLM,我们可以简化并分解它,使其只需处理其擅长的任务,如推理或流畅沟通。RAG就是一个例子。不再依赖LLM根据其内部知识来检索和排名项目,我们可以通过增加外部知识来增强LLM,并专注于应用LLM的推理能力。
监控:这有助于展示人工智能系统的附加价值,或者缺乏附加价值。有人分享了一个轶事,他们在生产环境中运行了基于LLM的客户支持解决方案两周,然后停止使用——A/B测试显示,当使用LLM代替他们的支持团队时,损失增加了12倍!
(阅读更多关于机器学习代码和系统的设计模式。)
此外,这是其他人说的:
结论
这是我迄今为止写过最长的帖子。如果你还在继续阅读,谢谢你!我希望你觉得阅读这些模式的介绍有帮助,并且下面的2x2图表能够让你理解。

LLM模式跨越数据到用户的轴线,并从防守转向进攻。
我们在构建基于LLM的系统和产品的旅程中仍然处于早期阶段。有没有我错过的关键模式或资源?你发现有什么有用或无用的东西?我很想听听你的经验。请联系我!
参考文献Hrycks,Dan等人。《测量大规模多任务语言理解》。arXiv预印本arXiv:2009.03300(2020年)。
高,Leo等。“一种用于少样本语言模型评估的框架。”,Zenodo,(2021),doi:10.5281/
梁,Percy等人。“语言模型的整体评估。”arXiv预印本arXiv:2211.09110(2022年)。
Papineni,Kishore等人。“Bleu:一种用于自动评估机器翻译的方法。”计算语言学协会第40届年会论文集。2002年。
林钦耀。“Rouge:自动摘要评估工具包。”文本摘要分支扩展。2004年。
张天一等人。“Bertscore:使用Bert评估文本生成。”arXiv预印本arXiv:1904.09675(2019)。
赵,魏等人。“MoverScore:使用上下文嵌入和地球移动距离评估文本生成。”arXiv预印本arXiv:1909.02622(2019年)。
Sai,AnanyaB.,AkashKumarMohankumar,“用于自然语言生成系统的评估指标综述。”ACMComputingSurveys(CSUR)55.2(2022):1-39.
刘,杨等人。“Gpteval:使用GPT-4进行更好人类对齐的NLG评估。”arXiv预印本arXiv:2303.16634(2023年)。
Fourrier,Clémentine等人。“OpenLLM排行榜出了什么问题?”(2023年)。
郑,连民等。“使用MT-Bench和ChatbotArena评估LLM作为法官。”arXiv预印本arXiv:2306.05685(2023年)。
Dettmers,Tim等人。《Qlora:高效微调量化的LLM模型》。arXiv预印本arXiv:2305.14314(2023)。
Swyx等人的MPT-7B和Context=Infinity的开端(2023年)。
Fradin,Michelle,Reeder,Lauren“TheNewLanguageModelStack”(2023).
Radford,Alec等人。“从自然语言监督中学习可迁移的视觉模型。”机器学习国际会议。PMLR,2021年。
严子友。“搜索:通过词汇、图形和嵌入方法进行查询匹配。”,(2021)。
Petroni,Fabio等人。“上下文如何影响语言模型的事实预测。”arXiv预印本arXiv:2005.04611(2020年)。
Karpukhin,Vladimir等人。“用于开放领域问答的密集段落检索。”arXiv预印本arXiv:2004.04906(2020年)。
Lewis,Patrick等人。《检索增强的生成模型用于知识密集型自然语言处理任务》。《神经信息处理系统进展》第33卷(2020年):9459-9474。
Izacard,Gautier,和EdouardGrave.“利用生成模型提升开放领域问答中的段落检索。”arXiv预印本arXiv:2007.01282(2020).
Borgeaud,Sebastian等人。“通过从数万亿个标记中检索来改进语言模型。”机器学习国际会议。PMLR,(2022年)。
Lazaridou,Angeliki等人。“通过少量提示进行互联网增强的语言模型,用于开放领域的问答。”arXiv预印本arXiv:2203.05115(2022年)。
王,岳等人。“Codet5+:用于代码理解和生成的开源大型语言模型。”arXiv预印本arXiv:2305.07922(2023年)。
高,陆宇等人。“无相关标签的精确零样本密集检索。”arXiv预印本arXiv:2212.10496(2022年)。
严子友。“黑曜石副驾驶:写作与反思的助手。”,(2023)。
Bojanowski,Piotr等人。“用子词信息丰富词向量。”计算语言学协会交易5(2017):135-146。
Reimers,Nils和IrynaGurevych.“使用知识蒸馏将单语句嵌入多语言化。”2020年经验方法在自然语言处理会议论文集,计算语言学协会,(2020年)。
王,梁等人。“弱监督对比预训练的文本嵌入。”arXiv预印本arXiv:2212.03533(2022年)。
苏洪金等人。“一个嵌入器,多种任务:经过指导微调的文本嵌入。”arXiv预印本arXiv:2212.09741(2022年)。
Johnson,Jeff等人。“使用GPU进行十亿级相似性搜索。”《IEEETransactionsonBigData》,第7卷,第3期,IEEE,2019年,页码535-47。
Malkov,YuA.和“使用分层可导航小世界图的高效稳健近似最近邻搜索。”《IEEE模式分析与机器智能交易》,第42卷,第4期,IEEE,2018年,页码824-36。
郭瑞琪等人。“利用各向异性矢量量化加速大规模推断。”机器学习国际会议,(2020年)
Howard,Jeremy,和SebastianRuder.“通用语言模型微调用于文本分类。”arXiv预印本arXiv:1801.06146(2018).
Devlin,Jacob等人。“Bert:预训练深度双向转换器用于语言理解。”arXiv预印本arXiv:1810.04805(2018年)。
Radford,Alec等人。“通过无监督学习提高语言理解能力。”(2018年)。
Raffel,Colin等人。《探索统一文本到文本转换器的迁移学习极限》。机器学习研究杂志21.1(2020):5485-5551。
Lester,Brian,RamiAl-Rfou,和NoahConstant.“参数高效的提示调整的规模优势。”arXiv预印本arXiv:2104.08691(2021).
李翔丽和梁佩西。“前缀调优:优化生成任务的连续提示。”arXiv预印本arXiv:2101.00190(2021年)。
侯尔斯比(Houlsby)、尼尔(Neil)等人。“用于自然语言处理的参数高效迁移学习。”机器学习国际会议。PMLR,2019年。
胡,爱德华J.等。“Lora:大型语言模型的低秩适应。”arXiv预印本arXiv:2106.09685(2021年)。
Dettmers,Tim等人。《Qlora:高效微调量化的LLM模型》。arXiv预印本arXiv:2305.14314(2023)。
威廉姆斯,阿迪娜等人。“一个用于通过推理进行句子理解的广泛覆盖挑战语料库。”2018年北美计算语言学协会会议论文集:人类语言技术,第1卷(长篇论文),计算语言学协会,(2018年)。
GPTCache(2023年)。
护栏(2023年)
NeMo-Guardrails(2023)
Manakul,Potsawee,AdianLiusie和MarkJFGales.“Selfcheckgpt:Zero-resourceblack-boxhallucinationdetectionforgenerativelargelanguagemodels.”arXiv预印本arXiv:2303.08896(2023).
指导(2023年)。
Amershi,Saleema等人。“人工智能与人类互动的指南。”2019年人机交互计算系统CHI会议论文集。2019年。
人工智能指南(2023年)。
机器学习的人机界面指南(2023年)。
Schel,ZacharyA.,FarazFarzin,andSiddhiSundar.“AHumanPerspectiveonAlgorithmicSimilarity.”
如果您觉得这篇文章有用,请引用本文:
免责声明:本文章如果文章侵权,请联系我们处理,本站仅提供信息存储空间服务如因作品内容、版权和其他问题请于本站联系